本文转自公众号燃梦说
摘要:90年代末机器学习兴起,2012年,神经网络概念复辟,而在AlphaGo碾压人类选手后,强化学习卷土重来。近26年来,AI领域基本没有新的概念出现,只有不同的技术一次次从冷宫中解放出来。
麻省理工科技评论在1月25日发布的一篇文章中,分析了截至2019年11月18日,论文数据库中arXiv的16625份关于AI的论文。
从分析结果看,“AI”概念的风靡,有三个典型时期:90年代末21世纪初机器学习兴起,2010年代初神经网络概念复辟,近几年强化学习概念卷土重来。
值得注意的是,arXiv的AI论文模块始于1993年,而“人工智能”的概念可以追溯到1950年,因此这一数据库只能反馈近26年以来的AI研究。而且,arXiv每年收录的论文,也仅代表当时人工智能领域的一部分研究。不过,它仍然是观测AI行业研究趋势的最佳窗口。
我们接下来就来看一下,16625份论文提供了哪些信息。
起点:解救程序员
基于知识的系统,由人类将知识赋予计算机,而计算机承担知识的存储和管理功能,帮助人类解决问题。转变为机器学习后,计算机可以自主学习所有的人类知识。这是21世纪以来AI研究最大的转变。
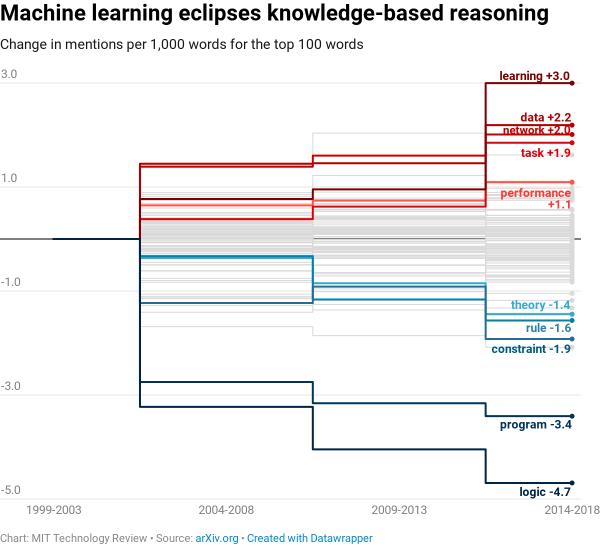
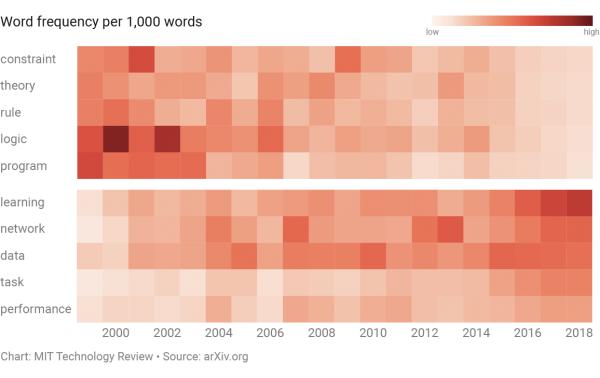
在相关论文提及率最高的100个单词中,“逻辑”“约束”“规则”等基于知识系统的词语,自90年代以来出现率显著下降,而“数据”“网络”“性能”增长最为明显。
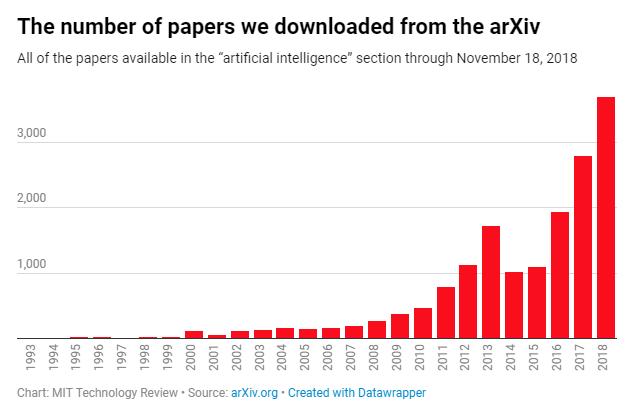
麻省理工科技评论称,这种变化的原因非常好理解。上世纪80年代,基于知识的系统广受欢迎,但各种各样的项目推进的同时,研究者遇到了一个问题:需要编写太多太多的规则,才能让计算机作出有效决策,这种成本太过高昂,研究者的动力也就随之减少。
机器学习实际上是解决这个问题的方案。机器学习让计算机从一系列数据中提取规则,把程序员从编码“逻辑”“规则”“约束”中解救了出来。
神经网络井喷
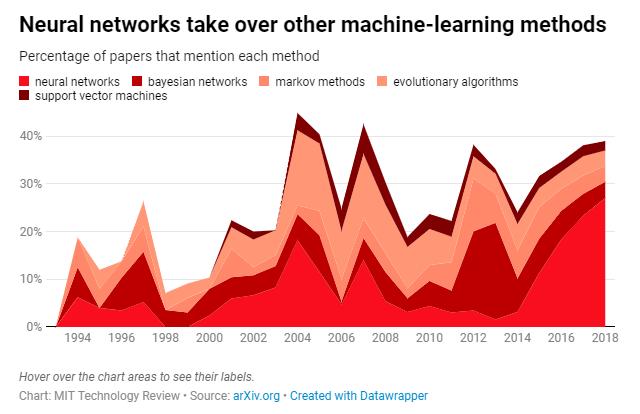
机器学习开始登上舞台,但是向深度学习的转变并没有马上出现。神经网络是深度学习的核心机制,但麻省理工科技评论对16625篇论文关键字检索的结果显示,研究者还尝试了各种其他“提取规则”的方法,包括贝叶斯网络、马尔可夫模型、进化算法和支持向量机(support vector machines,SVM)等。
上世纪90年代到21世纪初,这些方法都在相互竞争。一直到2012年,视觉识别领域一年一度的ImageNet竞赛中,多伦多大学的Geoffrey Hinton教授和两个学生(Ilya Sutskever 和Alex Krizhevsky)的AlexNet横空出世,把图像识别的Top-5错误率(给出的前N个答案中有一个是正确答案的概率)降低到了15.3%,比亚军的26.5%低了41%)。
为了构建识别成千上万图像的系统,该团队采用了卷积神经网络。为避免数据过度拟合,AlexNet采用的神经网络还使用了数据扩充(平移、翻转等),以及随机(概率为0.5)“删除”(dropout)一些神经元来减少工作量等。
Geoffrey Hinton教授当时强调,深度对最终的识别精度尤为重要。深度学习技术由此引起了广泛关注。它从图像识别领域逐渐扩展开来,神经网络概念也随之井喷。
强化学习兴起
在深度学习推广数年后,人工智能发生了迄今为止的最后一次重要转变,即强化学习的兴起。
机器学习算法可以分为三种:有监督的学习,无监督的学习,以及强化学习。
有监督的学习给机器提供已经标记过的数据,机器学习的那些行为都是正确的行为。例如,标记过的花卉数据集告诉正在学习的机器模型,哪些照片分别是玫瑰、雏菊和水仙。而在给出一张测试图像时,机器应该把它和学习的数据进行对比,判断那是玫瑰、雏菊还是水仙。
有监督的学习最适用于解决有参照背景的问题。例如物品分类,或是基于面积、位置和公交便利程度判断住宅价格。所以,它是是最常用的也是最实用的机器学习算法。
标记数据集并不容易,所以也有无监督的学习。提供给无监督学习的数据集没有特定的期望结果,或是正确答案。机器需要自己提取特征和规律,来理解数据。
无监督学习的应用场景,包括银行通过账户异常行为判断虚假交易,电商通过已经加入到购物车的产品,推荐相关的其他产品等。
过去几年里,强化学习在研究领域的出现频率迅速提高。强化学习同样也采用未经标记的数据,但与无监督学习不同地是,强化学习还模拟了训练动物地过程,对进行学习的机器提供“奖惩机制”,在执行最优解时提供反馈。
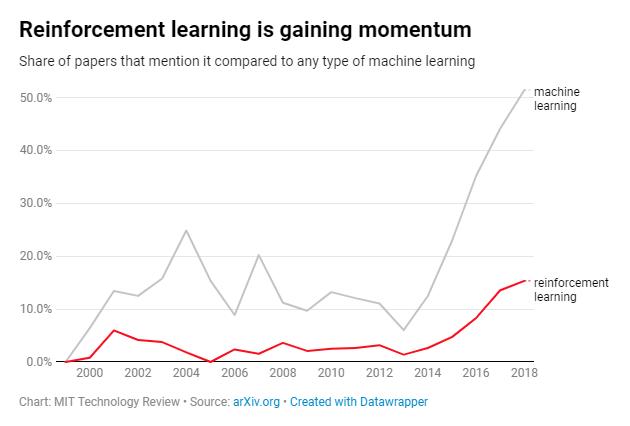
和深度学习一样地,强化学习也是通过里程碑式的突破,才引起了研究者的注意。2015年,DeepMind的AlphaGo在强化学习训练下,成长为可以击败代表人类最高水平的围棋棋手,让埋没数十年地强化学习再次走到大众视线中。
而游戏本身,也是强化学习最好的渠道——它的奖励机制足够明确。在机器作出了正确选择后,它会获得“胜利”的反馈,而这样的反馈越多,机器越能选择正确的策略。
下一个十年的AI趋势
从过去二十多年的经验来看,人工智能领域并没有出现什么明显的新技术。各种技术在研究界的地位起起落落,但热门的种种技术,许多都起源于同一时间,即上世纪50年代左右。
以神经网络为例,它在60年代统治AI届,80年代也有些存在感,而在2012年卷土重来之前,这一概念濒临灭绝。
每一个10年里,都有不同的技术统领AI研究,华盛顿大学教授、The Master Alogrithm一书作者Pedro Domingos 称,2020年代也不会有什么不同,意味着深度学习的时代可能也很快就要终结。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2019-1-29 15:01:43 |
2019-1-29 15:01:43 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}