转自公众号数据派THU
一、背景介绍:赌场风云
最近一个赌场的老板发现生意不畅,于是派出手下去赌场张望。经探子回报,有位大叔在赌场中总能赢到钱,玩得一手好骰子,几乎是战无不胜。而且每次玩骰子的时候周围都有几个保镖站在身边,让人不明就里,只能看到每次开局,骰子飞出,沉稳落地。老板根据多年的经验,推测这位不善之客使用的正是江湖失传多年的"偷换骰子大法”(编者注:偷换骰子大法,用兜里自带的骰子偷偷换掉均匀的骰子)。老板是个冷静的人,看这位大叔也不是善者,不想轻易得罪他,又不想让他坏了规矩。正愁上心头,这时候进来一位名叫HMM帅哥,告诉老板他有一个很好的解决方案。
不用近其身,只要在远处装个摄像头,把每局的骰子的点数都记录下来。
然后HMM帅哥将会运用其强大的数学内力,用这些数据推导出:
该大叔是不是在出千?
如果是在出千,那么他用了几个作弊的骰子? 还有当前是不是在用作弊的骰子?
这几个作弊骰子出现各点的概率是多少?
天呐,老板一听,这位叫HMM的甚至都不用近身,就能算出是不是在作弊,甚至都能算出别人作弊的骰子是什么样的。那么,只要再当他作弊时,派人围捕他,当场验证骰子就能让他哑口无言。
二、HMM是何方神圣?
在让HMM开展调查活动之前,该赌场老板也对HMM作了一番调查。
HMM(Hidden Markov Model), 也称隐性马尔可夫模型,是一个概率模型,用来描述一个系统隐性状态的转移和隐性状态的表现概率。
系统的隐性状态指的就是一些外界不便观察(或观察不到)的状态, 比如在当前的例子里面, 系统的状态指的是大叔使用骰子的状态,即
{正常骰子, 作弊骰子1, 作弊骰子2,...}
隐性状态的表现也就是可以观察到的,由隐性状态产生的外在表现特点。这里就是说, 骰子掷出的点数.
{1,2,3,4,5,6}
HMM模型将会描述,系统隐性状态的转移概率。也就是大叔切换骰子的概率,下图是一个例子,这时候大叔切换骰子的可能性被描述得淋漓尽致。
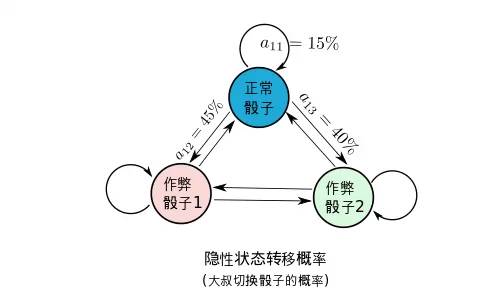
很幸运的,这么复杂的概率转移图,竟然能用简单的矩阵表达, 其中a_{ij}代表的是从i状态到j状态发生的概率:

当然同时也会有,隐性状态表现转移概率。也就是骰子出现各点的概率分布, (e.g. 作弊骰子1能有90%的机会掷到六,作弊骰子2有85%的机会掷到'小’)。给个图如下:
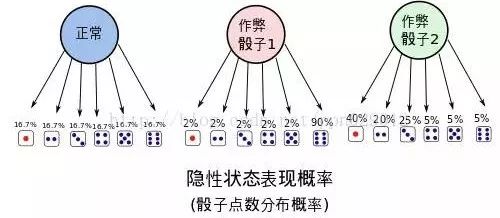
隐性状态的表现分布概率也可以用矩阵美丽地表示出来:

把这两个东西总结起来,就是整个HMM模型。
这个模型描述了隐性状态的转换的概率,同时也描述了每个状态外在表现的概率的分布。总之,HMM模型就能够描述扔骰子大叔作弊的频率(骰子更换的概率),和大叔用的骰子的概率分布。有了大叔的HMM模型,就能把大叔看透,让他完全在阳光下现形。
三、HMM能干什么!
总结起来HMM能处理三个问题,
3.1 解码(Decoding)
解码就是需要从一连串的骰子中,看出来哪一些骰子是用了作弊的骰子,哪些是用的正常的骰子。
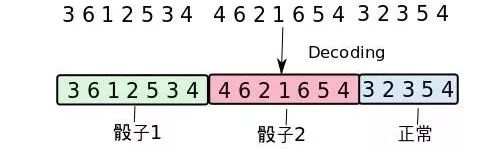
比如上图中,给出一串骰子序列(3,6,1,2..)和大叔的HMM模型, 我们想要计算哪一些骰子的结果(隐性状态表现)可能对是哪种骰子的结果(隐性状态).
3.2 学习(Learning)
学习就是,从一连串的骰子中,学习到大叔切换骰子的概率,当然也有这些骰子的点数的分布概率。这是HMM最为恐怖也最为复杂的招数!!
3.3 估计(Evaluation)
估计说的是,在我们已经知道了该大叔的HMM模型的情况下,估测某串骰子出现的可能性概率。比如说,在我们已经知道大叔的HMM模型的情况下,我们就能直接估测到大叔扔到10个6或者8个1的概率。
四、HMM是怎么做到的?
(这章需要概率论,递归,动态规划的知识, 如果不感兴趣可以跳着第5节)
4.1 估计
估计是最容易的一招,在完全知道了大叔的HMM模型的情况下,我们很容易就能对其做出估计。
现在我们有了大叔的状态转移概率矩阵A,B就能够进行估计。比如我们想知道这位大叔下一局连续掷出10个6的概率是多少? 如下
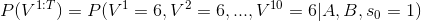
这表示的是,在一开始隐性状态(s0)为1,也就是一开始拿着的是正常的骰子的情况下,这位大叔连续掷出10个6的概率。
现在问题难就难在,我们虽然知道了HMM的转换概率,和观察到的状态V{1:T}, 但是我们却不知道实际的隐性的状态变化。
好吧,我们不知道隐性状态的变化,那好吧,我们就先假设一个隐性状态序列, 假设大叔前5个用的是正常骰子, 后5个用的是作弊骰子1.
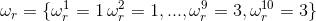
好了,那么我们可以计算,在这种隐性序列假设下掷出10个6的概率.
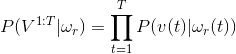
这个概率其实就是,隐性状态表现概率B的乘积.
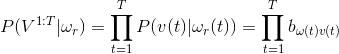
但是问题又出现了,刚才那个隐性状态序列是我假设的,而实际的序列我不知道,这该怎么办。好办,把所有可能出现的隐状态序列组合全都试一遍就可以了。于是,
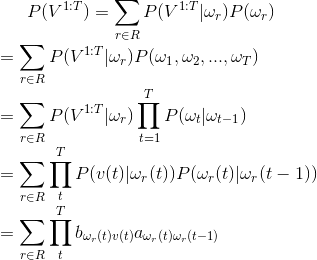
R就是所有可能的隐性状态序列的集合。的嗯,现在问题好像解决了,我们已经能够通过尝试所有组合来获得出现的概率值,并且可以通过A,B矩阵来计算出现的总概率。
但是问题又出现了,可能的集合太大了, 比如有三种骰子,有10次选择机会, 那么总共的组合会有3^10次...这个量级O(c^T)太大了,当问题再大一点时候,组合的数目就会大得超出了计算的可能。所以我们需要一种更有效的计算P(V(1:T)概率的方法。
比如说如下图的算法可以将计算P(V1:T)的计算复杂度降低至O(cT).

有了这个方程,我们就能从t=0的情况往前推导,一直推导出P(V1:T)的概率。下面让我们算一算,大叔掷出3,2,1这个骰子序列的可能性有多大(假设初始状态为1, 也就是大叔前一次拿着的是正常的骰子)?
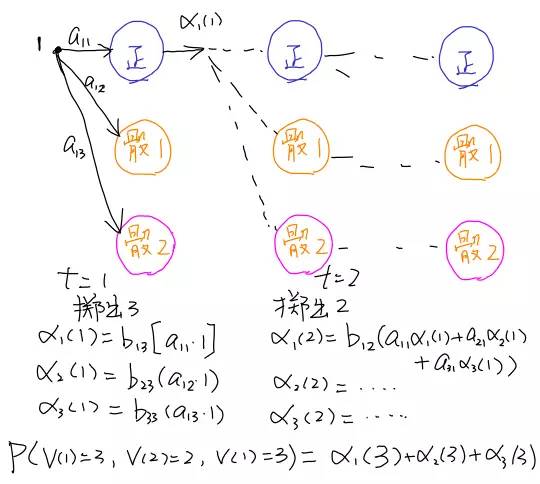
4.2 解码(Decoding)
解码的过程就是在给出一串序列的情况下和已知HMM模型的情况下,找到最可能的隐性状态序列。
用数学公式表示就是, (V是Visible可见序列, w是隐性状态序列, A,B是HMM状态转移概率矩阵)
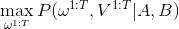
还记得以下公式:
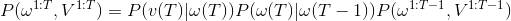
然后又可以使用估计(4.1)中的前向推导法,计算出最大的P(w(1:T), V(1:T)).
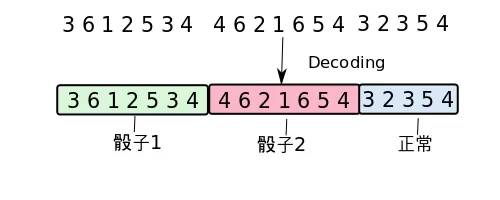
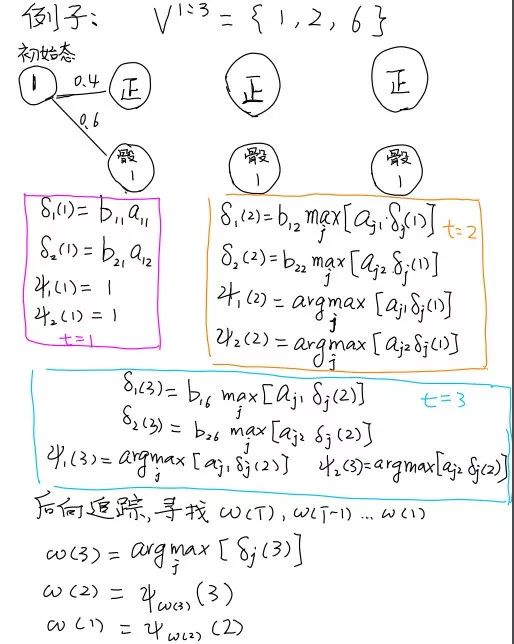
在完成前向推导法之后,再使用后向追踪法(Back Tracking),对求解出能令这个P(w(1:T), V(1:T))最大的隐性序列。这个算法被称为维特比算法(Viterbi Algorithm).
维特比算法找寻最有可能的隐性序列

这是动态规划算法的一种, 解法都是一样的, 找到递归方程后用前向推导求解.然后使用后向追踪法找到使得方程达到最优解的组合. 以下是一个计算骰子序列{1,2,6}最有可能的隐性序列组合.(初始状态为1=正常骰子,)
4.3 学习(Learning)
学习是在给出HMM的结构的情况下(比如说假设已经知道该大叔有3只骰子,每只骰子有6面),计算出最有可能的模型参数.
在假设完HMM的结构以后,就可以使用EM(Expectation Maximization) 算法最大化Likelihood. 这里的最大似然是,
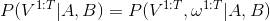
我们要做的就是,找到能使似然最大的函数.所以这个问题又转化成了"最大似然估计问题(MLE)". 在MLE问题中需要估计隐含参量时,就需要用到EM算法(EM具体算法推导可参考JerryLead的博客)进行估计.
五、HMM 的应用
以上举的例子是用HMM对掷骰子进行建模与分析。当然还有很多HMM经典的应用,能根据不同的应用需求,对问题进行建模。
但是使用HMM进行建模的问题,必须满足以下条件,
隐性状态的转移必须满足马尔可夫性。(状态转移的马尔可夫性:一个状态只与前一个状态有关)
隐性状态必须能够大概被估计。
在满足条件的情况下,确定问题中的隐性状态是什么,隐性状态的表现可能又有哪些。
HMM适用于的问题在于,真正的状态(隐态)难以被估计,而状态与状态之间又存在联系。
5.1 语音识别
语音识别问题就是将一段语音信号转换为文字序列的过程. 在个问题里面
隐性状态就是: 语音信号对应的文字序列
而显性的状态就是: 语音信号.
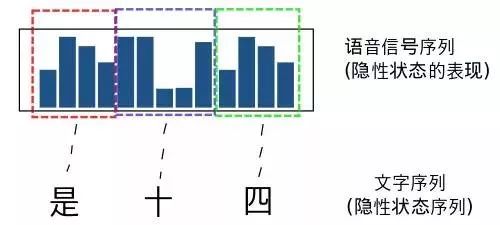
HMM模型的学习(Learning):语音识别的模型学习和上文中通过观察骰子序列建立起一个最有可能的模型不同. 语音识别的HMM模型学习有两个步骤:
统计文字的发音概率,建立隐性表现概率矩阵B
统计字词之间的转换概率(这个步骤并不需要考虑到语音,可以直接统计字词之间的转移概率即可)
语音模型的估计(Evaluation): 计算"是十四”,"四十四"等等的概率,比较得出最有可能出现的文字序列.
5.2 手写识别
这是一个和语音差不多,只不过手写识别的过程是将字的图像当成了显性序列.
5.3 中文分词
“总所周知,在汉语中,词与词之间不存在分隔符(英文中,词与词之间用空格分隔,这是天然的分词标记),词本身也缺乏明显的形态标记,因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序。
例如,英文句子:you should go to kindergarten now 天然的空格已然将词分好,只需要去除其中的介词“to”即可;而“你现在应该去幼儿园了”这句表达同样意思的话没有明显的分隔符,中文分词的目的是,得到“你/现在/应该/去/幼儿园/了”。
那么如何进行分词呢?主流的方法有三种:
第1类是基于语言学知识的规则方法,如:各种形态的最大匹配、最少切分方法;
第2类是基于大规模语料库的机器学习方法,这是目前应用比较广泛、效果较好的解决方案.用到的统计模型有N元语言模型、信道—噪声模型、最大期望、HMM等。
第3类也是实际的分词系统中用到的,即规则与统计等多类方法的综合。使用HMM进行中文分词。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2019-1-16 14:45:47 |
2019-1-16 14:45:47 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}