本文转自智能运维前沿
AIOps最有挑战性的算法之一是根因分析,也就是搞清楚故障是如何一步步传播并最终导致业务故障的。这里面就涉及到机器学习里非常难的分支-因果推断。有多难?大家先看看这个烧脑的统计学悖论。
我们平时在做重大决策的时候,比如择校啊,选专业啊,总是会参考这些比较对象的硬指标,比如它们的录取率啊,就业率啊等等。像是,哪个学校的就业率高,我们就会去报考这个学校。
统计数字可以帮助我们了解这些比较对象的优劣,让我们做出明智的决策。不光是个人,公司和国家也是这样做决策的。那么这样做对吗?
其...实...不...对
今天我们就来介绍一个让人非常头疼,但非常有用的悖论,它会告诉你,很多时候统计数字相当不可靠,特别容易误导人。
先来看一个假设的例子。
小明生了慢粒白血病,她的失散多年的哥哥找到有2家比较好的医院,医院A和医院B供小明选择就医。
小明的哥哥多方打听,搜集了这两家医院的统计数据,它们是这样的:
医院A最近接收的1000个病人里,有900个活着,100个死了。
医院B最近接收的1000个病人里,有800个活着,200个死了。
作为对统计学懵懵懂懂的普通人来说,看起来最明智的选择应该是医院A对吧,病人存活率很高有90%啊!总不可能选医院B吧,存活率只有80%啊。
呵呵,如果小明的选择是医院A,那么她就中计了。
就这么说吧,如果医院A最近接收的1000个病人里,有100个病人病情很严重,900个病人病情并不严重。
在这100个病情严重的病人里,有30个活下来了,其他70人死了。所以病重的病人在医院A的存活率是30%。
而在病情不严重的900个病人里,870个活着,30个人死了。所以病情不严重的病人在医院A的存活率是96.7%。
在医院B最近接收的1000个病人里,有400个病情很严重,其中210个人存活,因此病重的病人在医院B的存活率是52.5%。
有600个病人病情不严重,590个人存活,所以病情不严重的病人在医院B的存活率是98.3%。
画成表格,就是这样的——

你可以看到,在区分了病情严重和不严重的病人后,不管怎么看,最好的选择都是医院B。但是只看整体的存活率,医院A反而是更好的选择了。所谓远看是汪峰,近看白岩松,就是这个道理。
这让人很抓狂。万一我们真的患上了什么病,又遇到了这种类似的情况,岂不是会让自己掉坑里?大韩民国这么多小明就是因为这个原因去世的吗?到底这是怎么回事?
实际上,我们刚刚看到的例子,就是统计学中著名的黑魔法之一——辛普森悖论(Simpson's paradox)。辛普森悖论最初是英国数学家爱德华·H·辛普森(Edward H. Simpson)在1951年发现的。
辛普森悖论就是当你把数据拆开细看的时候,细节和整体趋势完全不同的现象。
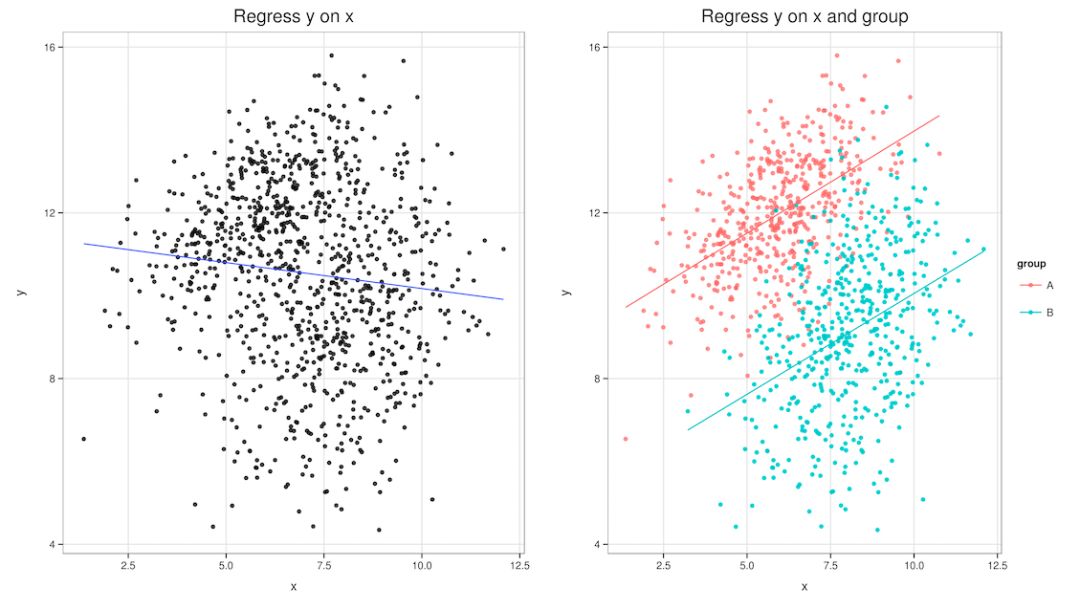
辛普森悖论:同一组数据,整体的趋势和分组后的趋势完全不同。
从统计学家的观点来看,出现辛普森悖论的原因是因为这些数据中潜藏着一个魔鬼——潜在变量(lurking variable),比如在上面这个例子里,潜在变量就是病情严重程度不同的病人的占比。
辛普森悖论在日常生活中层出不穷。
最著名的辛普森悖论的实例,就是1973年加利福尼亚大学伯克利分校性别歧视案的例子。

加利福尼亚大学伯克利分校
大家从表格里可以看到,如果只看整体录取率,那么男生的录取率是44%,女生的是35%。
不求甚解的话,一般人肯定会得出这样的结论——女生被歧视了。打算申请这所著名大学的女生要是看到这样的数据,八成肺都气炸了。

别急,现在把上面的数据按照院系拆分,再来看看每个系的录取率。

你可以看到,在6个院系的4个里,女生的录取率大于男生,女生只在2个院系里容易折戟。加利福尼亚大学伯克利分校的统计学教授Peter Bickel 后来发现,如果按照这样的分类,女生实际上比男生的录取率还高一点点。
Bickel 认为,在这个案例中,辛普森悖论出现的原因是,女生更愿意申请那些竞争压力很大的院系(比如英语系),但是男生却更愿意申请那些相对容易进的院系(比如工程学系)。辛普森悖论真是太奇怪了。
再比如这个经典的佛罗里达死刑悖论。
1991年,科罗拉多大学的统计学家Michael L. Radelet 和东北大学的社会学研究院主任Glenn Pierce 重新查看了1976-1987年间美国佛罗里达州的谋杀案的审判数据,发现了重大的司法不公正事件。
从归总的数据来看,佛罗里达的法官在审判的时候并没有偏向白人,因为白人嫌疑人的死刑率甚至还比黑人高一些。

但是,如果按照被害人的种族来分割数据的话,我们就会看到很不一样的结果了——黑人比白人更容易被判死刑。

现在你可以很明显地看出,不管被害人是什么种族,黑人比白人更有可能被判死刑。
这还不算。分类后的数据显示,如果受害人是白人,那么嫌疑人就更容易被判死刑。如果被害人是黑人,嫌疑人被判死刑的可能性很低。种族歧视昭然若揭啊。
所以,我们要怎样才能避免辛普森悖论呢?
答案是…很难。不少统计学家认为,辛普森悖论的存在,让我们不可能光用统计数字来推导准确的因果关系。
因为数据可以用各种各样的方式分类,然后再进行比较,所以理论上潜在变量无穷无尽,你总是可以用某个潜在变量得到某种结论。
而且对于那些不怀好意的人来说,他们很容易对数据进行拆分或者归总,得到一个对自己有利的指标,从而来迷惑甚至操纵他人。医学和社会学的研究者也常常会遇到辛普森悖论,从而得出错误的结论。
辛普森悖论完美地阐释了这句古老的哲学寓言:“假如一棵树在森林里倒下而没有人在附近听见,它有没有发出声音?”如果有一个邪恶的潜在变量逃脱了你的眼睛,那么统计数字得出的结论还可信吗?
我们能做的,就是仔细地研究分析各种影响因素,不要笼统概括地、浅尝辄止地看问题。
什么,你要我举个利用辛普森悖论操纵别人的例子?
很简单啊。那些常说“我是聪明的小朋友里最漂亮的,漂亮的小朋友里最聪明的”小孩,一般都是既不_____,也不_____的。
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-12-10 10:19:31 |
2018-12-10 10:19:31 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}