转自公众号微软研究院AI头条
编者按:在我们的生活中,用语音查询天气,用必应搜索信息,这些常见的场景都离不开一种应用广泛的数据存储方式——表格(table)。如果让表格更智能一些,将是怎么样的呢?在这篇文章中,微软亚洲研究院自然语言计算组将为我们介绍基于表格的自然语言理解与生成方向的一系列工作。
表格(table)是一种应用广泛的数据存储方式,被广泛用于存储和展示结构化数据。由于表格数据结构清晰、易于维护、时效性强,它们通常是搜索引擎和智能对话系统的重要答案来源。例如,现代搜索引擎(如必应搜索引擎)基于互联网表格直接生成问题对应的答案;虚拟语音助手(如微软Cortana、亚马逊Alexa等)结合表格和自然语言理解技术回答人们的语音请求,例如查询天气、预定日程等。
我们将在本文中介绍我们在基于表格的自然语言理解与生成方向的一系列工作,包括检索(retrieval)、语义解析(semantic parsing)、问题生成(question generation)、对话(conversation)和文本生成(text generation)等五个部分。除了检索任务,其余四个任务的目标均是在给定表格的基础上进行自然语言理解和生成:
检索:从表格集合中找到与输入问题最相关的表格;
义解析:将自然语言问题转换成可被机器理解的语义表示(meaning representation,在本文中是SQL语句),在表格中执行该表示即可获得答案;
问题生成:可看作语义解析的逆过程,能减轻语义解析器对大量标注训练数据的依赖;
对话:主要用于多轮对话场景的语义解析任务,需有效解决上下文中的省略和指代现象;
文本生成:使用自然语言描述表格中(如给定的一行)的内容。
让我们用一张图概括本文接下来所要涉及的内容。
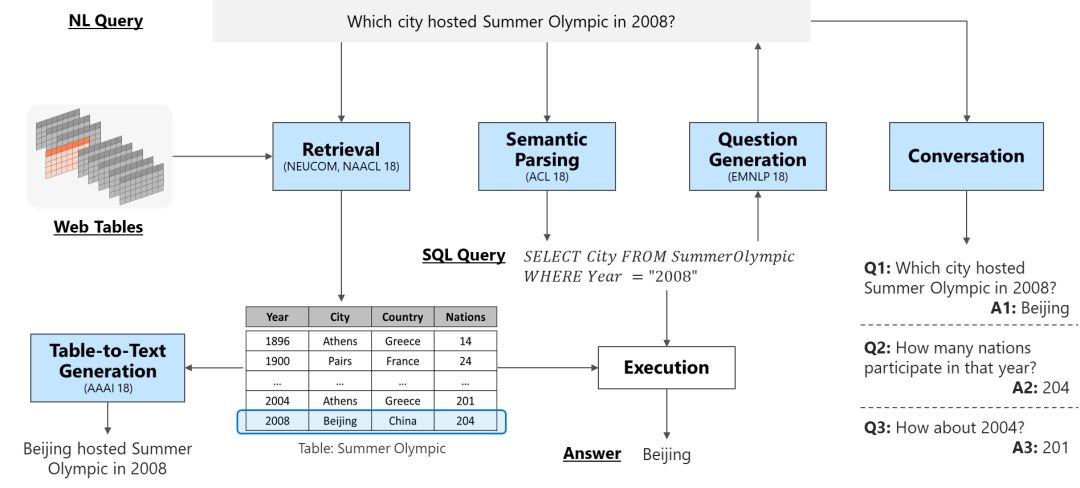
检索Retrieval
对于给定的自然语言q和给定的表格全集T={T1, T2, .., Tn},表格检索任务的目的是从T中找到与q内容最相关的表格,如下图所示。每个表格通常由三部分构成:表头/列名(table header)、表格单元(table cell)和表格标题(table caption)。
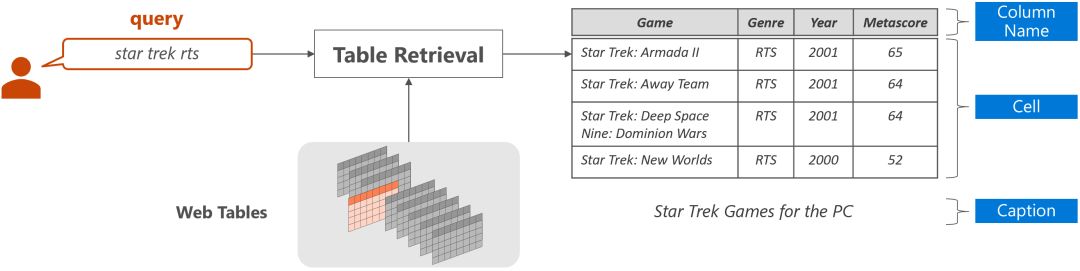
表格检索的关键在于衡量自然语言问题和表格之间的语义相关程度。一个基本的做法是把表格看做文档,使用文本检索中常用的字符串相似度计算方法(如BM25)计算自然语言问题和表格之间的相似度。也有学者使用更多样的特征,如表格的行数、列数、问题和表格标题的匹配程度等。
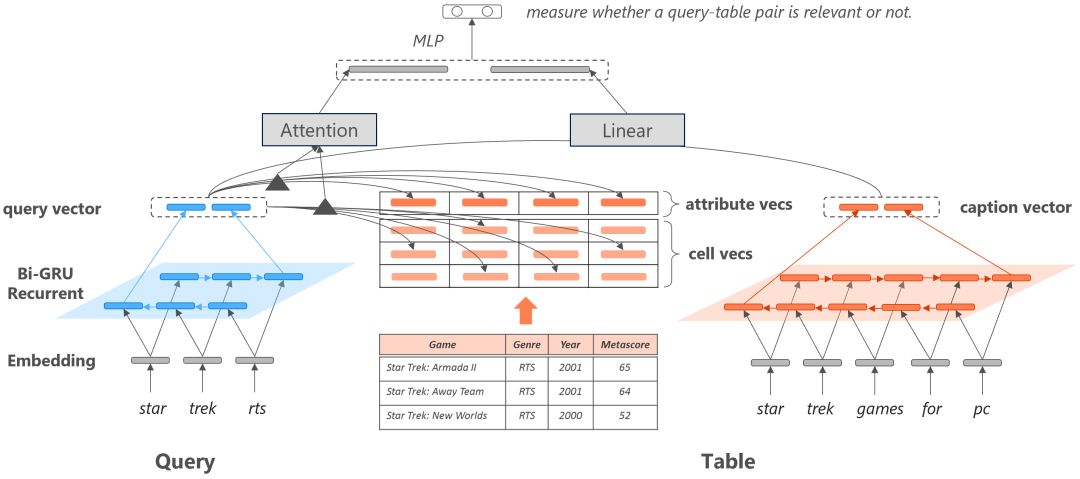
为了更好地融入表格的结构信息,我们提出了一个基于神经网络的表格检索模型,在语义向量空间内分别计算问题和表头、问题和列名、问题和表格单元的匹配程度,如下图所示。由于问题和表格标题都是词序列,我们均使用双向GRU把二者分别表示为向量表示,最终使用线性层计算二者的相关度。由于表头和表格单元不存在序列关系,任意交换表格的两列或两行应保证具有相同的语义表示,所以我们使用Attention计算问题和表头以及问题和表格单元的相关度。
由于目前表格检索的公开数据集有限,因此我们构建了一个包含21,113个自然语言问题和273,816个表格的数据集。在该数据集上,我们对比了基于BM25的系统、基于手工定义特征的系统以及基于神经网络的系统,结果如下表所示。
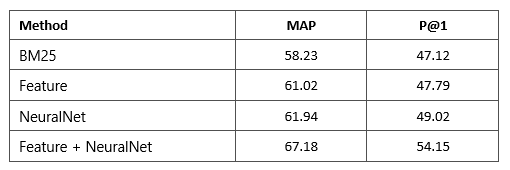
可以看出基于神经网络的算法与手工设计的特征性能相近,二者相结合可以进一步提高系统的性能。
更多细节请参照论文:
Yibo Sun, Zhao Yan, Duyu Tang, Nan Duan, Bing Qin. Content-Based Table Retrieval for Web Queries. 2018. Neurocomputing.
语义解析 Semantic Parsing
给定一张网络表格,或一个关系数据库表,或一个关于表的自然语言问句,语义解析的输出是机器可以理解并执行的规范语义表示(formal meaning representation),在本小节我们使用SQL语句作为规范语义表示,执行该SQL语句即可从表中得到问题的答案。
目前,生成任务比较流行的方法是基于序列到序列(sequence to sequence)架构的神经模型,一般由一个编码器(encoder)和一个解码器(decoder)组成。编码器负责建模句子表示,解码器则根据编码器得到的问句表示来逐个从词表中挑选出一个个符号进行生成。
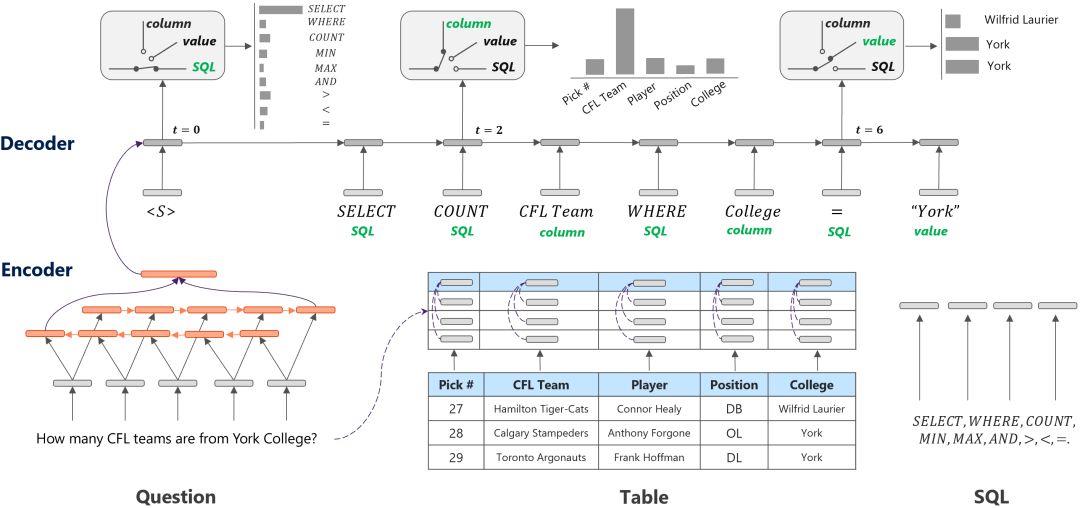
然而,SQL语句遵循一定的语法规则,一条SQL查询语句通常由3种类型的元素组成,即SQL关键词(如SELECT, WHERE, >, < 等)、表格的列名和WHERE语句中的条件值(通常为数字或表格单元)。因此,我们在解码器端融入SQL的语法信息,具体由一个门单元和三个频道组成。门单元负责判断该时刻即将输出符号的类型,三个频道分别为Column、value、SQL频道,在每个频道中分别预测表中列名称、表中单元格名称和SQL语法关键字。该算法在WikiSQL数据集上性能优于多个强对比算法。
更多细节可以参考论文:
Yibo Sun, Duyu Tang, Nan Duan, Jianshu Ji, Guihong Cao, Xiaocheng Feng, Bing Qin, Ting Liu and Ming Zhou. Semantic Parsing with Syntax- and Table-Aware SQL Generation. 2018. ACL.
问题生成Question Generation
统计机器学习算法的性能通常受有指导训练数据量的影响。例如,我们使用上一小节提出的语义解析算法,在有不同指导训练数据的条件下观察模型的性能(这里的有指导训练数据指的是人工标注的“问题-SQL”对)。下表中x轴是log scale的训练数据量,可以发现语义解析的准确率与训练数据量之间存在Log的关系。
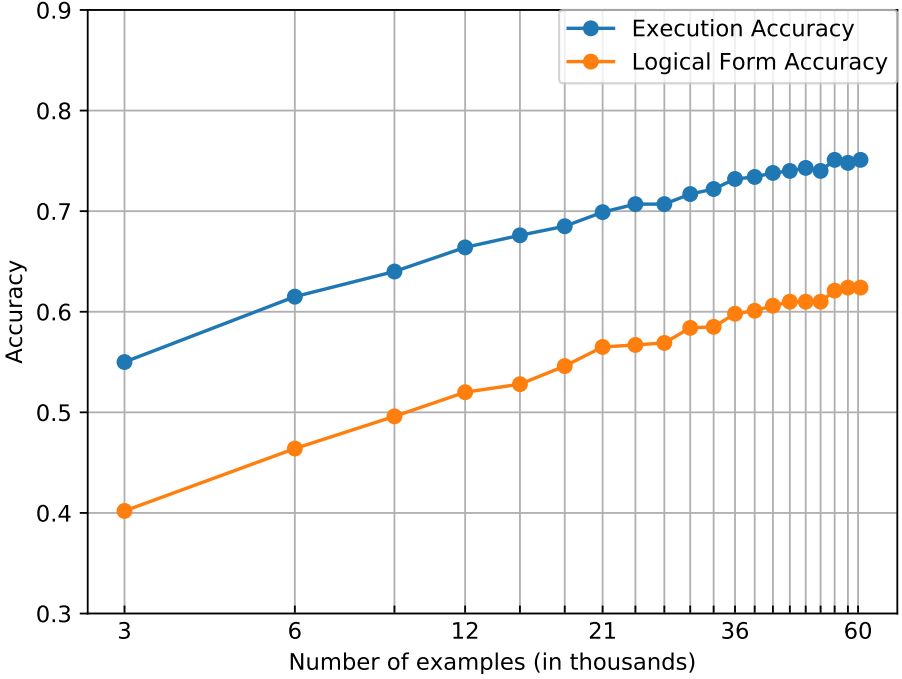
基于上述观察,我们希望使用少量的有指导训练数据,达到同样的语义分析准确率。为此,我们提出了一个基于问题生成的语义分析训练框架,如下图所示。给定一个表格,我们首先使用一个基于规则的SQL采样器生成SQL语句,随后用一个在小规模有指导数据上训练的问题生成模型生成多个高置信度的问题,将新生成的数据与小规模的有指导数据结合,共同训练语义分析模型。另外,问题生成模型是基于Seq2Seq模型,为了增加生成问题的多样性我们在解码器端加入了隐含变量。
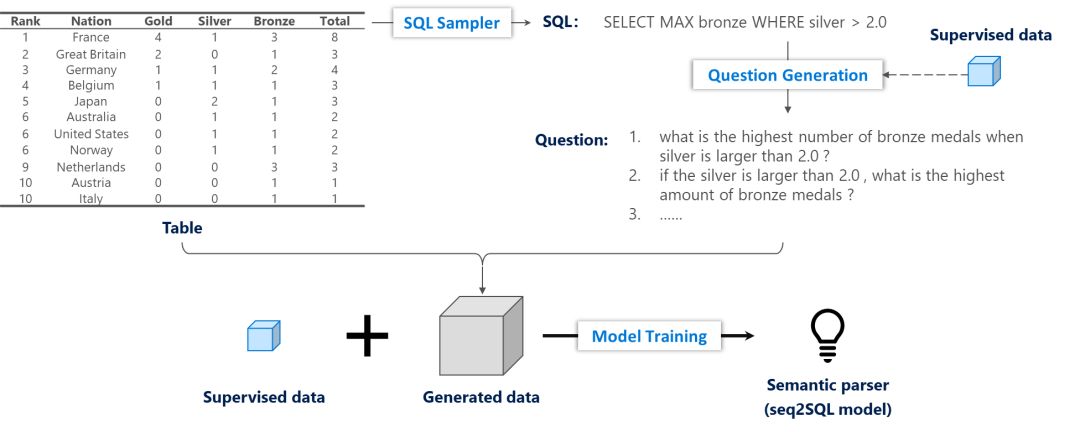
更多细节可以参考论文:
Daya Guo, Yibo Sun, Duyu Tang, Nan Duan, Jian Yin, Hong Chi, James Cao, Peng Chen and Ming Zhou. Question Generation from SQL Queries Improves Neural Semantic Parsing. 2018. EMNLP.
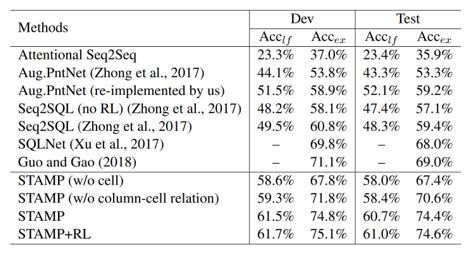
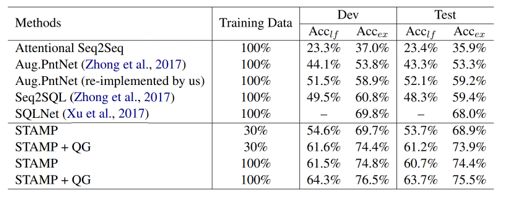
我们在WikiSQL数据集上进行实验,使用上一章中所介绍的算法(STAMP)作为基本模型。从下表可以看出,融合问题生成模型的训练算法可以在30%训练数据的条件下达到传统训练算法100%训练数据的性能。使用该算法,在100%训练数据的条件下会进一步提升模型的性能。
对话Conversational Semantic Parsing
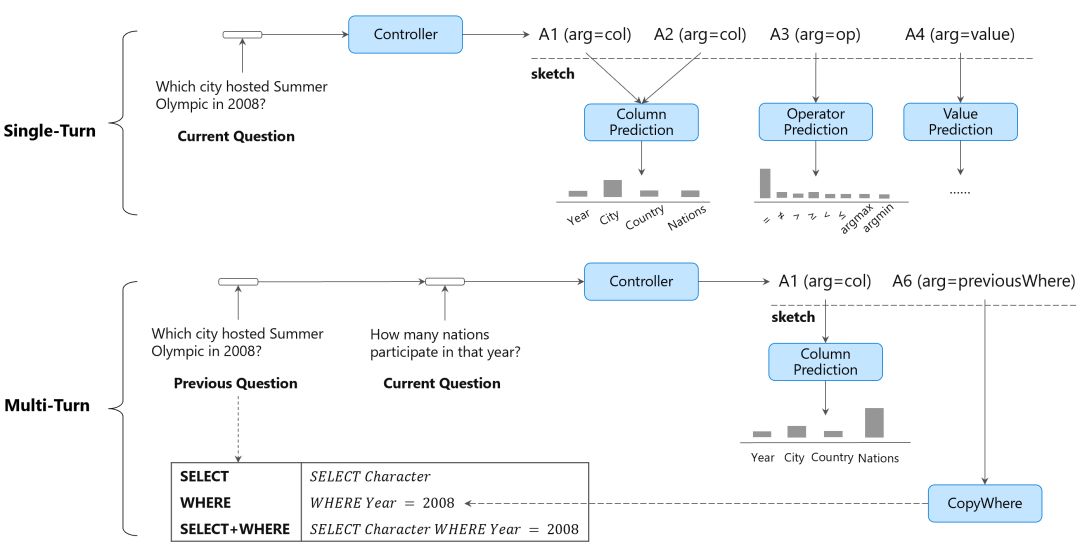
前面我们介绍的语义解析算法针对的都是单轮问答场景,即用户针对一个表格每次问一个独立的问题。而在对话场景下,人们会在前一个问题的基础上继续提问,通常人们会使用指代或省略使对话更加简洁和连贯。例如,在下图的例子中,第2个问句中的”that year”指代第一个问句中提及的年份;第3个问题更是直接省略了问题的意图。

针对多轮对话场景下的语义分析,我们以Sequence-to-Action的形式生成问题的语义表示,在该模式下生成一个语义表示等价于一个动作序列,Sequence-to-Action在单轮和多轮语义分析任务中均被验证是非常有效的方法。
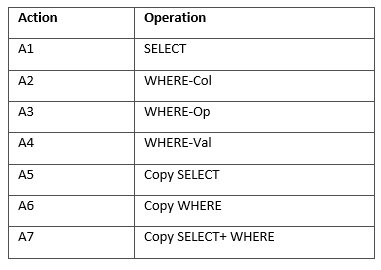
具体地,我们在Mohit Iyyer等人发表在ACL 2017上的研究Search-based Neural Structured Learning for Sequential Question Answering的基础上定义了如下表的动作集合,作为我们Sequence-to-Action模型的语法基础。A1-A4的目的是根据当前语句的内容预测SELECT语句中的列名、WHERE语句中的列名、WHERE语句中的操作符(如=, >, <)和WHERE语句中的条件值;A5-A7的目的是从上一句的历史语义表示中复制部分内容到当前语句的语义表示中。
我们以下图为例介绍模型的工作原理。输入历史问题和当前问题,该模型首先使用Controller模块预测当前问句的动作序列骨架(即未实例化的动作序列),随后使用特定的模型(如基于Attention的column prediction模块)去实例化骨架中的每个单元。当模型预测A5-A7(如下图中所展示的A6),模型实现了复制历史语义表示的功能。
更多细节请参考论文:
Yibo Sun, Duyu Tang, Nan Duan, Jingjing Xu, Xiaocheng Feng, Bing Qin. Knowledge-Aware Conversational Semantic Parsing Over Web Tables. 2018. Arxiv.
自然语言生成Table-to-Text Generation
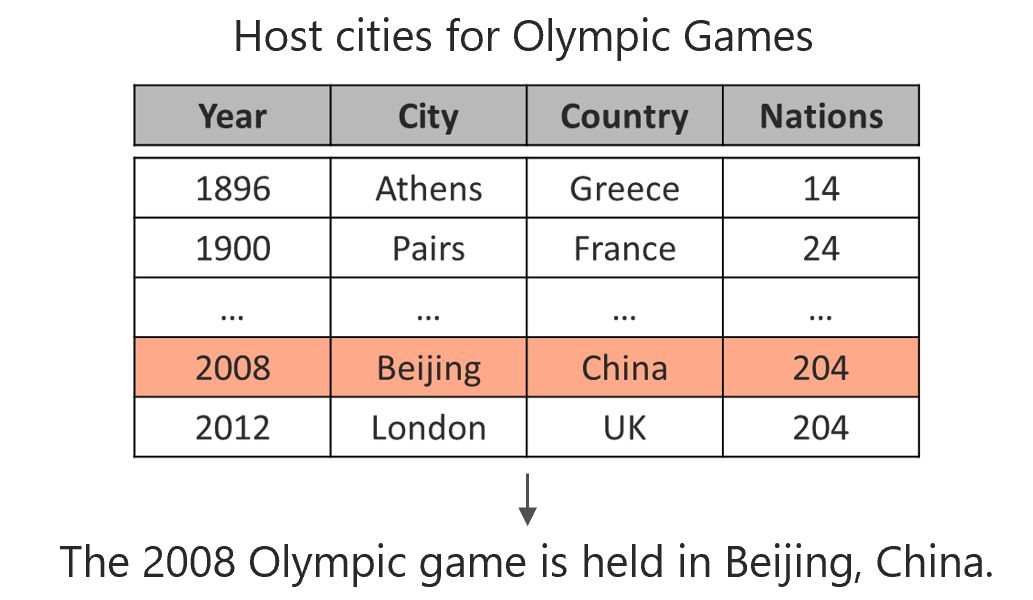
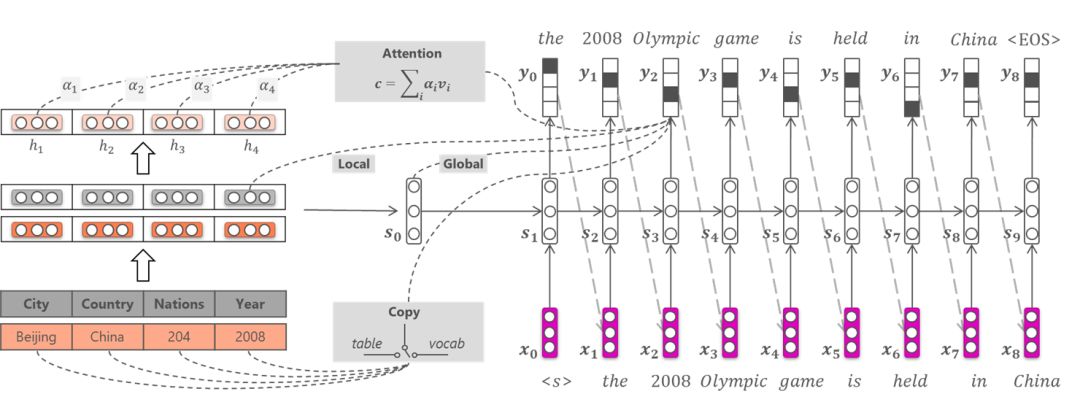
很多场景都需要用自然语言形式呈现答案。因此我们基于表格的文本生成工作,目的是用自然语言描述表格中(如给定的一行)的内容。以下图为例,给定表格中的一行,输出一句完整的描述内容。
我们的模型基于Sequence-to-Sequence框架,如下图所示。为了考虑表格的结构性(如打乱表格的各列不改变其表示),我们在编码器模块没有使用序列化的形式去建模各个列的表示;为了有效从表格中复制低频词到输出序列,我们设计了基于表格结构的复制机制。
具体内容请参考论文:
Junwei Bao, Duyu Tang, Nan Duan, Zhao Yan, Yuanhua Lv, Ming Zhou, Tiejun Zhao. Table-to-Text: Describing Table Region with Natural Language. 2018. AAAI.
本文介绍了我们在基于表格的自然语言理解与生成相关的5项工作。目前,与表格相关的自然语言处理研究刚刚起步,方法尚未成熟,对应的标注数据集也相对有限,我们希望与业界研究者们一起共同探索新的方法和模型,推动该领域的进一步发展。
作者简介



唐都钰,微软亚洲研究院自然语言计算组研究员,主要从事包括智能问答、语义理解、常识推理等在内的自然语言处理基础研究。

孙一博,微软亚洲研究院自然语言计算组的实习生,目前就读于哈尔滨工业大学。研究兴趣包括问答系统、语义分析和深度学习等。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-10-24 14:27:43 |
2018-10-24 14:27:43 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}