转发自公众号AI火箭营
一、强化学习的兴起
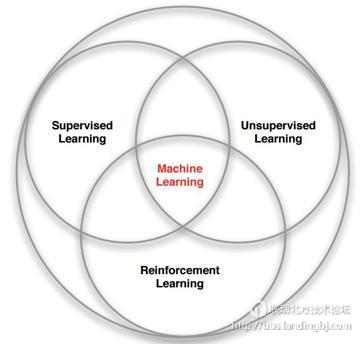
2013 年伦敦的一家公司 DeepMind 发表了一篇论文 Playing Atari with Deep Reinforcement Learning 。论文描述了如何教会电脑玩 Atari 2600 游戏。结果很令人满意:电脑比大多数人类玩家玩的好,并且在没有任何改变的情况下,该模型学会了玩其他游戏,在3个游戏中比人类玩家玩的好!最后, DeepMind 因此被谷歌看中而被收购。2015年,DeepMind 又发表了一篇 Human-level control through deep reinforcement learning,在本篇论文中 DeepMind 用同样的模型,教会电脑玩49种游戏,而且过半游戏比专业玩家玩得更好。2016年3月,AlphaGo 与围棋世界冠军、职业九段选手李世石进行人机大战,并以4:1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以"大师"(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩。自此,在机器学习领域,除了监督学习和非监督学习,强化学习(Reinforcement Learning)也逐渐走进人们的视野。
二、什么是强化学习?
强化学习是一个序列决策问题,它需要连续选择一些行为,从而这些行为完成后得到收益最好的结果。它在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈,然后由这个反馈来决定当前的行为,通过不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
强化学习和其他机器学习范式有什么不同:
没有大量标注数据进行监督,所以也就不能由样本数据告诉系统什么是最可能的动作,训练主体只能从每一步动作得出奖励。因此系统是不能立即得到标记的,而只能得到一个反馈,也可以说强化学习是一种标记延迟的监督学习。
时间序列的重要性,强化学习不像其他接受随机输入的学习方法,其更注重序列型数据,并且下一步的输入经常依赖于前一状态的输入。
延迟奖励的概念,系统可能不会在每步动作上都获得奖励,而只有当完成整个任务时才会获得奖励。
训练实体的动作影响下一个输入。如你可以选择向左走或向右走,那么当选择的方向不同时,下一个时间步的输入也会不同。即选择不同的动作进入不同的状态后,当前可选的动作又不一样。
以著名的打砖块游戏为例,游戏中你控制底部的挡板来反弹小球,来清除屏幕上半部分的砖块。每次你打中砖块,分数增加,你也得到一个奖励,而没有接到小球则会受到惩罚。
假设让一个神经网络来玩这个游戏, 输入是屏幕图像,输出将是三个动作:左,右或发射球。表面看这是个分类问题,对于每一帧图像,采取一个动作即可(为屏幕数据分类)。但球发出去之后的运动轨迹是动态变化的,这就决定了我们:当前的时刻在变化的状态,决定了我们的动作,而采取的动作又决定了未来的状态和动作奖励。不像监督学习,强化学习没有标签,只有一个时间延迟的奖励,而且游戏中我们往往牺牲当前的奖励来获取将来更大的奖励。我们的小球在打到砖块,获得奖励时,事实上挡板并没有移动,该奖励是由于之前的一系列动作来获得的。而且在我们找到一个策略,让游戏获得不错的奖励时,我们是选择继续坚持当前的策略,还是探索新的策略以求更多的奖励?这就是强化学习中探索与开发(Explore-exploit Dilemma)的问题。
强化学习就是一个重要的解决此类问题的模型,它是从我们的人类经验中总结出来的。在现实生活中,如果我们做某件事获得奖励,那么我们会更加偏向于做这件事。
强化学习有两个很重要的问题,一个是累积收益,不能只看眼前的一步决策,采用简单粗暴的用贪心策略,而要看多个序列决策的作用。二是要考虑交互过程状态转移的不确定性,目标是求解累积收益的期望最大化,而不能简单理解为能用if else表达的动态规划。
三、强化学习组成
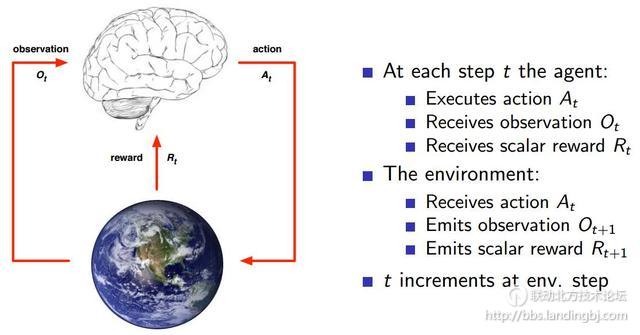
强化学习决策流程见上图。需要构造出一个agent(图中的大脑部分),agent能够执行某个action,例如游戏中代表你的小人朝哪个方向走,围棋棋子下在哪个位置。agent接收当前环境的一个observation,例如当前机器人的摄像头拍摄到场景。agent还能接收它执行某个action后的reward。而环境environment则是agent交互的对象,它是一个行为不可控制的对象,agent一开始不知道环境会对不同action做出什么样的反应,而环境会通过observation告诉agent当前的环境状态,同时环境能够根据可能的最终结果反馈给agent一个reward,例如围棋棋面就是一个environment,它可以根据当前的棋面状况估计一下黑白双方输赢的比例。reward奖赏,是一个反馈标量值,它表明了agent做出的决策有多好或者有多不好,整个强化学习优化的目标就是最大化累积reward。
四、转化为数学问题
那么如何用数学的方法来解决此类问题呢?马尔可夫决策过程 (Markov Decision Process)。
MDP 中有两个对象:Agent和 Environment。我们图示如下:
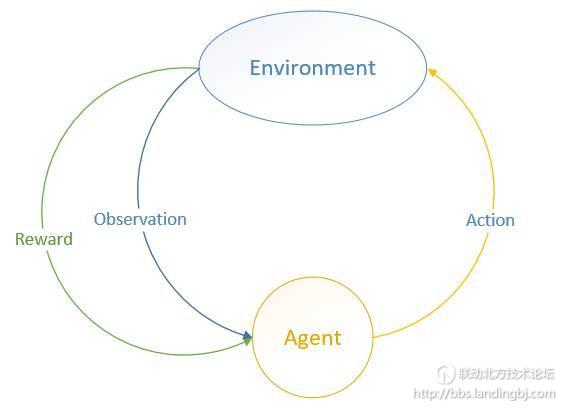
Environment处于一个特定的状态(State)(如打砖块游戏中挡板的位置、各个砖块的状态等),Agent可以通过执行特定的动作( Actions)(如向左向右移动挡板)来改变Environment的状态, Environment状态改变之后会返回一个观察(Observation)给Agent,同时还会得到一个奖励(Reward)(可以为负,就是惩罚),这样 Agent根据返回的信息采取新的动作,如此反复下去。Agent如何选择动作叫做策略(Policy)。MDP 的任务就是找到一个策略,来最大化奖励。
注意 State和 Observation区别:State是 Environment的私有表达,我们往往不知道不会直接到的。
在 MDP 中,下一个状态的产生跟所有历史状态是有关的,也就是等式右边所示。但是Markov的定义则是忽略掉历史信息,只保留了当前状态的信息来预测下一个状态,这就叫Markov:
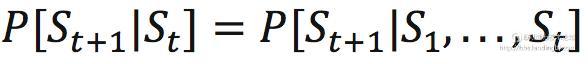
对于一个具体的状态s和它的下一个状态s' ,它们的状态转移概率(就是从s转移到s'的概率)定义为:
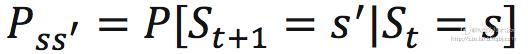
假如总共有n种状态可以选择。那么状态转移矩阵P定义为:
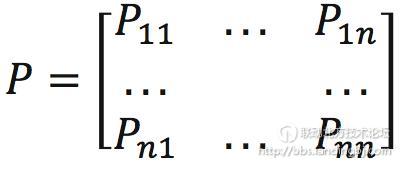
矩阵中第i行表示,如果当前状态为i,那么它的下一个状态为1, … , n的概率分别为Pi1,...,Pin。显然,这一行所有概率之和为1.
状态、动作、状态转移概率(S, A, P)组成了 MDP,一个 MDP 周期(episode )由一个有限的状态、动作、奖励队列组成。
在马尔科夫过程中,只有状态和状态转移概率,没有在状态情况下动作的选择,将动作(策略)考虑在内的马尔科夫过程称为马尔科夫决策过程。强化学习,简单的说就是考虑了动作策略的马尔科夫过程,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。强化学习是依靠环境给予的奖惩来学习的,因此对应的马尔科夫决策过程还包括奖惩值R,其可以由一个四元组构成M= (S, A, P, R)。
强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略,策略就是状态到动作的映射,使得最终的累计回报最大。
该贴被liuliying930406编辑于2018-10-10 15:04:46
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-10-10 10:34:48 |
2018-10-10 10:34:48 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}