
【导读】随着深度学习方法的应用,浏览器调用人脸识别技术已经得到了更广泛的应用与提升。在实际过程中也具有其特有的优势,通过集成与人脸检测与识别相关的API,通过更为简单的coding就可以实现。今天将为大家介绍一个用于人脸检测、人脸识别和人脸特征检测的 JavaScript API,通过在浏览器中利用 tensorflow.js 进行人脸检测和人脸识别。大家不仅可以更快速学习这个,对有人脸识别技术需求的 JS 开发者来说更是一件值得开心的事。
前言
对于 JS 开发者来说这将是一件很开心的事,那就是终于可以在浏览器中进行人脸识别了!通过接下来的这篇文章,将为大家介绍 face-api.js,一个构建在 tensorflow.js core 上的 javascript 模块,实现了人脸检测、人脸识别和人脸特征检测三种 CNNs (卷积神经网络)。
我们将通过研究一个简单的代码示例,只用几行代码就可以试着使用这个包。
第一个人脸识别包 face-recognition.js,现在又来了一个包?
如果读过我的另一篇关于人脸识别的文章 Node.js + face-recognition.js : Simple and Robust Face Recognition using Deep Learning,你可能会了解到在不久前,我组装了一个类似的包, face-recognition.js,用 nodejs 来进行人脸识别。
起初,我没有想到在 javascript 社区对人脸识别包的需求会如此之高。对很多人来说,face-recognition.js 就像微软或亚马逊所提供的,似乎是一个不错的可免费使用且开源的替代付费服务的人脸识别服务。但我经常也会被问到一个问题,在浏览器中是或否可以完全运行完整的人脸识别管道。
对此要感谢 tensorflow.js !我使用 tfjs-core 实现了部分类似的工具,得到与 face-recognition.js 几乎相同的结果,但,是在浏览器中实现的!而最棒的一点是,它不需要设置任何外部依赖关系,就可以直接使用。还有一个意外的奖励 —— 在 WebGL 上运行操作 ,GPU 的加速。
这足以让我相信,javascript 社区需要这样一个包!这也将留给你们足够的想象空间,你们可以用它来构建各种各样的应用。
如何用深度学习解决人脸识别问题
如果你是希望尽快开始,你可以跳过这一部分,直接跳到编码中。但是为了更好地理解 face-api.js 使用的方法。要实现人脸识别,强烈建议参与一起学习,因为我经常会被问到这个问题。
简单来说,我们实际上想要实现的是,识别给出的一个人的面部图像,用作输入图像(input image)。
我们的方法是,给出想识别的那个人的一张或多张图片,并给此人的名字打上标签,用作参考数据(reference data)。现在将输入图片与引用数据进行对比并找出最相似的参考图片。如果两个图像足够相似,我们将会输出此人的名字,否则我们输出结果为 “unknow”。
听起来不错吧!然而这其中还存在两个问题。首先,如果一张照片中有多人并且我们想把所有人都识别出来该怎么办?其次,我们需要能够计算出两张人脸图像的相似度度量,以便比较它们。
人脸检测
对于第一个问题的答案是通过人脸检测来解决。简单地说,我们首先定位输入图像中的所有面孔。人脸检测,face-api.js 实现了一个 SSD 算法,它基本上是基于 MobileNetV1 的 CNN,在网络的顶部有一些额外的盒预测层。
网络返回每张面孔的边界框与相应的分数,即显示面孔的每个边界框的概率。这些分数用于筛选边界区域,因为图像中可能根本不包含任何面孔。注意,即使只有一个人要检索边界框,人脸检测也应该执行。

人脸特征检测和人脸对齐
第一个问题解决了!但是,我们想要对齐边界框,这样我们就可以在传递给人脸识别网络之前,在每个区域的人脸中心提取出图像,这将使人脸识别更加准确!
为此 face-api.js 实现了一个简单的 CNN 网络,此网络返回给定人脸图像的 68 个点的面部特征。
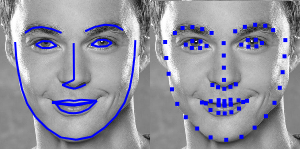
根据特征点的位置,边界区域可以集中在面部中心。在下图中你可以看到人脸检测的结果(左)与对齐的人脸图像(右)

人脸识别
现在我们可以将提取和对齐的人脸图像输入到人脸识别网络中,该网络是基于类似 ResNet-34 的架构,基本上对应于 dlib 中实现的架构。该网络已经被训练学习将人脸的特征映射到人脸描述符(一个有128个值的矢量)中,通常也被称为人脸嵌入。
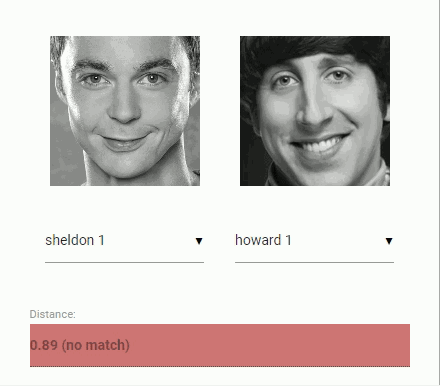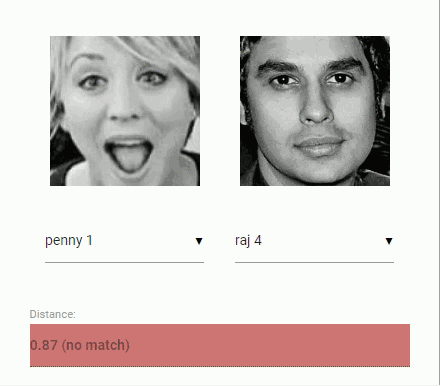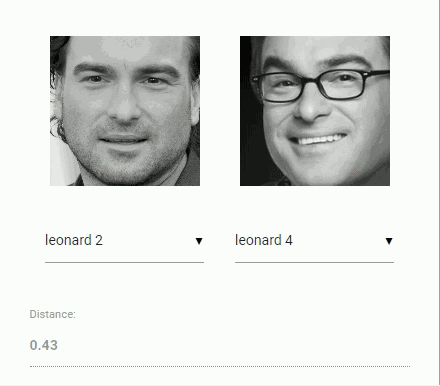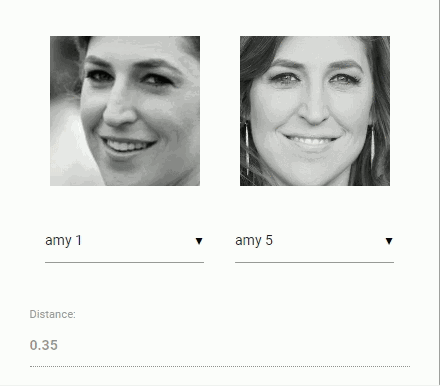
现在回到比较两个人脸时的原始问题:我们将使用提取的每张人脸图像的描述符,并将它们与参考数据的人脸描述符进行比较。更准确地说,我们可以计算两张人脸描述符之间的欧式距离,根据阈值判断两个人脸是否相似(对于 150×150 幅人脸图像,0.6 是一个很好的阈值)。使用欧几里得距离方法非常有效,当然你也可以选择任意类型的分类器。下面的 gif 图像例子就是通过欧几里得距离来比较的两张人脸图像:
在学过了人脸识别的理论之后,我们开始 coding ~~
编码
在这个简短的示例中,我们将逐步看到如何在下面这张多人的输入图像上进行人脸识别:

脚本
首先,从 dist / face - api .js上或者 dist/face-ap.min.js 的minifed版本中获取 latest build ,包括脚本:
<script src="face-api.js"></script>
如果用 npm :
npm i face-api.js
加载模型数据
根据你的应用需求,可以专门加载需要的模型,但是要运行一个完整的端到端示例,我们需要加载人脸检测、人脸特征检测和人脸识别这三个模型。模型文件在 repo 上可用,可在此找到。
链接:
https://github.com/justadudewhohacks/faceapi.js/tree/master/weights
和原始模型相比,已经量化了模型的权重,模型文件大小减少了75%,以允许客户端只加载所需要的最小数据。此外,模型的权重被分割成最大 4 MB的组块,使浏览器可以缓存这些文件,这样只需要加载一次。
模型文件可以作为静态资源来提供在给 web 应用程序,也可以在其他地方托管它们,通过指定文件的路径或 url 来加载它们。假设在 public/models 下一个模型目录中提供它们。
const MODEL_URL = '/models'
await faceapi.loadModels(MODEL_URL)
如果你只想加载特殊模块:
const MODEL_URL = '/models'
await faceapi.loadFaceDetectionModel(MODEL_URL)
await faceapi.loadFaceLandmarkModel(MODEL_URL)
await faceapi.loadFaceRecognitionModel(MODEL_URL)
从输入图像接收所有面孔的完整描述
神经网络接受 HTML 图像、画布或视频元素作为输入。简单地说,要检测输入的人脸的边界,只需使 Score > minScore
const minConfidence = 0.8
const fullFaceDescriptions = await faceapi.allFaces(input, minConfidence)
完整的脸部描述包含检测结果(边界框+分数)、脸部特征和计算描述符。faceapi.js 做了之前讨论所有的问题。也可以手动获取人脸位置和特征。github repo上有这样的示例。
注意,边界和特征与原始图像/媒体大小相关。如果显示的图像大小与原始图像大小不一致,可以调整它们的大小:
const resized = fullFaceDescriptions.map(fd => fd.forSize(width, height))
可以通过画出边界区域来可视化检测结果:
fullFaceDescription.forEach((fd, i) => {
faceapi.drawDetection(canvas, fd.detection, { withScore: true })
})

人间特征按照下面的方法显示出来
fullFaceDescription.forEach((fd, i) => {
faceapi.drawLandmarks(canvas, fd.landmarks, { drawLines: true })
})

人脸识别
知道了如何在输入图像中检索所有人脸的位置和描述符,我们将得到一些分别显示一个人的图像,并计算人脸描述符。这些描述符就是我们的参考数据。
假设我们有一些示例图像,我们首先用 url 获取图像。
然后使用 faceapi.bufferToImage 从数据缓存区中创建 HTML 图像元素:
// fetch images from url as blobs
const blobs = await Promise.all(
['sheldon.png' 'raj.png', 'leonard.png', 'howard.png'].map(
uri => (await fetch(uri)).blob()
)
)
// convert blobs (buffers) to HTMLImage elements
const images = await Promise.all(blobs.map(
blob => await faceapi.bufferToImage(blob)
))
接下来,对于每个图像,定位被试的脸并计算面部描述符,就像之前对输入图像所做的处理那样:
const refDescriptions = await Promsie.all(images.map(
img => (await faceapi.allFaces(img))[0]
))
const refDescriptors = refDescriptions.map(fd => fd.descriptor)
现在,剩下要做的就是循环遍历输入图像的人脸描述,找到与参考数据欧式距离最小的描述符:
const sortAsc = (a, b) => a - b
const labels = ['sheldon', 'raj', 'leonard', 'howard']
const results = fullFaceDescription.map((fd, i) => {
const bestMatch = refDescriptors.map(
refDesc => ({
label: labels[i],
distance: faceapi.euclideanDistance(fd.descriptor, refDesc)
})
).sort(sortAsc)[0]
return {
detection: fd.detection,
label: bestMatch.label,
distance: bestMatch.distance
}
})
正如前面讲到的,在这里用效果很好的欧氏距离作为相似度度量。最终得到了在输入图像中每个人的最佳匹配。
最后可以将边界框和它们的标签一起画出来并显示结果:
// 0.6 is a good distance threshold value to judge
// whether the descriptors match or not
const maxDistance = 0.6
results.forEach(result => {
faceapi.drawDetection(canvas, result.detection, { withScore: false })
const text = `${result.distance < maxDistance ? result.className : 'unkown'} (${result.distance})`
const { x, y, height: boxHeight } = detection.getBox()
faceapi.drawText(
canvas.getContext('2d'),
x,
y + boxHeight,
text
)
})

本文转自 人工智能头条
该贴被huang.wang编辑于2018-7-3 17:05:37
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2018-7-3 13:41:53 |
2018-7-3 13:41:53 |

 赞(
赞( 操作
操作
{kind=link}
{kind=link}