一.RAC 全局等待事件说明
在RAC环境中,和全局调整缓存相关的最常见的等待事件是global cache cr request,global cache busy和equeue。
当一个进程访问需要一个或者多个块时,Oracle会首先检查自己的Cache是否存在该块,如果发现没有,就会先通过global cache赋予这些块共享访问的权限,
然后再访问。假如,通过global cache发现这些块已经在另一个实例的Cache里面,那么这些块就会通过Cache Fusion,在节点之间直接传递,同时出现
global cache crrequest等待事件。
在10GB中,global cachecr request已经简称为gc crrequest。
从remote cache运输块到本地cache花费的时间还得看这些块是共享还是独占模式,如果块是共享(scur)的,Remote Cache就克隆信息传送过来,否则就要产生
一个PI,然后再传送过去。显然,global cache cr request等待事件和db file sequential/scatteredread 等待事件有着直接的关系。
通常,RAC中的进程会等待1s去尝试从本地或者远程Cache读取数据块信息,当然,这还得依靠块处于什么样的模式。如果超过了1s,那就表明节点之间连接、
慢,这个时候节点之间就使用private连接,而客户端的连接使用public,有时候,节点之间的连接, Cache Fusion就不会通过公共网络,在这种情况下,就
会有大量的global cachecr request等待事件出现,可以使用oradebugipc命令去验证下节点之间的连接是否使用了private network。
在下图中,上面的gc [current/cr] [multiblock] request实际上就是placeholder的event,图的左上角也做了说明。

gc [current/cr][multiblock] request实际上是表示了4个事件中的一个(gccurrent request、gc cr request、gc current multiblock request、gc cr
multiblock request)。
这里CR和current 是不同的概念,如果是读的话,那就是cr request,如果是更改的话,那就是current request。
Oracle 10g在很多地方区分了multi block request还是single block request,这样容易分析业务的数据特点。当在RAC环境下,一个session请求一个block
的时候,就会触发这个事件。
当请求一个block时,如果经过两个或者3个network hop就获得了该块的话,那就会产生gc [current/cr][2/3]-way。如果是3-way,那应该master和holder不
是同一个instance,如果是2-way,那就应该master和holder是同一个instance。这应该是最好的情况,请求后,就获得了请求的block即没有busy,也没有说
在请求的过程中等待。该类事件应该暗示是进行了block的网络传递,会产生流量,而grant 2-way的网络流量应该相对小。
gc [current/cr]block busy是说虽然也返回了,但是没有immediatesend,也就是控制流程返回了,但是实际的block并没有马上传递到requesterinstance,
gc[current/cr] block busy是和gc [current/cr] [2/3]-way对应的。
gc [current/cr]grant 2-way当请求一个block时,接收了一个message,该message应该是赋予了requester instance可以访问这个block。如果这个block没有
在local cache中,则随后的动作就是去磁盘上读该block。(插一点别的,Oracle的对数据的访问的控制,是在row级别和object级别,但是实际操作的对象却
是block,传递的对象也是block,对于一个block来说,会有一个master instance,也就是这个block的管理者,然后还有零到多个参与者,比如有的instance
为了读一致性,可能会在自己的local cache中存着该block的过去某个时间的image,有的instace为了修改该block,可能会在自己的local cache中存着该
block的past image)。
gc current grantbusy当一个instance请求一个block时,被告诉是busy的。不明白在什么情况下会产生grant busy的事件。
gc [current/cr][block/grant] congested对这几个事件的理解是无论对于current还是cr类型的block或者grant,都获得了事件,但是在过程中有拥堵。也就
是在内部的队列中等待超过1 ns(纳秒)。
gc [current/cr][failure/retry]这就是发生错误了,没有请求到block.
gc buffer busy是多个进程在同时访问一个block,造成锁竞争了。用RAC就一定要将各个节点隔离化,不管是通过业务隔离,区域隔离还是什么其他隔离手
段,最终的目的,就是要各个节点所承担的业务,访问不同的数据对象,最大可能地减少节点间的资源争用,才能发挥RAC集群系统的最大性能。
当会话从开始提交一致读的请求,到它获取请求信息,这个过程它是SLEEP状态的,对用户而言,看到的就是global cache cr request等待事件,而wait time
就是记录这个过程的时间。
通常,大量的global cache cr request主要有以下几个原因。
(1)节点之间内部连接慢或者节点之间传输带宽窄。这个可以通过重新连接获取高速连接。
(2)存在热点数据块的竞争。
(3)CPU负载过高或者LMS后台进程不够。正常情况下,只有两个LMS后台进程从CPU那里获取资源,增加LMS进程的数量或者提高它的优先权能够帮助从CPU那里
获取更多的资源。隐藏参数_lm_lms是设置LMS进程数量的。
(4)大量未提交的事务或者系统磁盘设备传输慢。
有关global cache的信息:
SQL> select name,value from v$sysstat where name like '%global cache%';
NAME VALUE
------------------------------------------------------
global cache gets 1791587
global cache get time 85911
global cache converts 179612
global cache convert time 1262
global cache cr blocks received 17189
global cache cr block receive time 31547
global cache current blocks received 4627
global cache current block receive time 763
global cache cr blocks served 16805
global cache cr block build time 72
global cache cr block flush time 25043
global cache cr block send time 54
global cache current blocks served 3529
global cache current block pin time 21
global cache current block flush time 0
global cache current block send time 15
global cache freelist waits 285
global cache defers 2
global cache convert timeouts 0
global cache blocks lost 0
global cache claim blocks lost 0
global cache blocks corrupt 0
global cache prepare failures 8
global cache skip prepare failures 3408
24 rows selected.
二.gc current/crblock busy等待事件
2.1 gc current block busy 等待事件
When a requestneeds a block in current mode, it sends arequest to the master instance. The requestor evenutally gets the blockvia cache
fusion transfer. However sometimes the block transfer isdelayed due to either the block was being used by a session on another instanceor
the block transfer was delayed because the holding instance could not writethe corresponding redo records to the online logfile
immediately.
--当请求的block是current模式,会发送一个请求到master 实例,最终请求者通过cache fusion获取到这个block。但是有时block在transfer过程中会有延
时,比如这个block正在被其他的block使用,或者持有block的实例不能及时的将redo records写入online logfile。
One can use thesession level dynamic performance views v$session and v$session_event to findthe programs or sesions causing the most waits
on this events
SQL>selecta.sid , a.time_waited , b.program , b.module from v$session_event a , v$sessionb where a.sid=b.sid and a.event='gc current block
busy' order by a.time_waited;
2.2 gc cr block busy 等待事件
When a requestneeds a block in CR mode, it sends arequest to the master instance. The requestor evenutally gets the block viacache fusion
transfer. However sometimes the block transfer is delayed due toeither the block was being used by a session on another instance or the
blocktransfer was delayed because the holding instance could not write thecorresponding redo records to the online logfile immediately.
One can use thesession level dynamic performance views v$session and v$session_event to find theprograms or sesions causing the most waits
on this events
SQL>selecta.sid , a.time_waited , b.program , b.module from v$session_event a ,v$session b where a.sid=b.sid and a.event='gc cr block
busy' order bya.time_waited;
2.3 相关说明
gc current blockbusy 等待是RAC中global cache全局缓存当前块的争用等待事件, 该等待事件时长由三个部分组成:
Time to process current block request inthe cache= (pin time + flush time + send time)
gc current block flush time
The currentblock flush time is part of the service (or processing) time for a currentblock. The pending redo needs to be flushed to the log file by LGWR before LMSsends it. The operation is asynchronous in that LMS queues the request, postsLGWR, and continues processing. The LMS would check its log flush queue forcompletions and then send the block, or go to sleep and be posted by LGWR. Theredo log write time and
redo log sync time can influence theoverall service time significantly.
flush time 是Oracle为了保证Instance Recovery实例恢复机制,而要求每一个current block在本地节点local instance被修改后(modify/update) 必须要将
该current block相关的redo 写入到logfile 后(要求LGWR必须完成写入后才能返回),才能由LMS进程传输给其他节点使用。
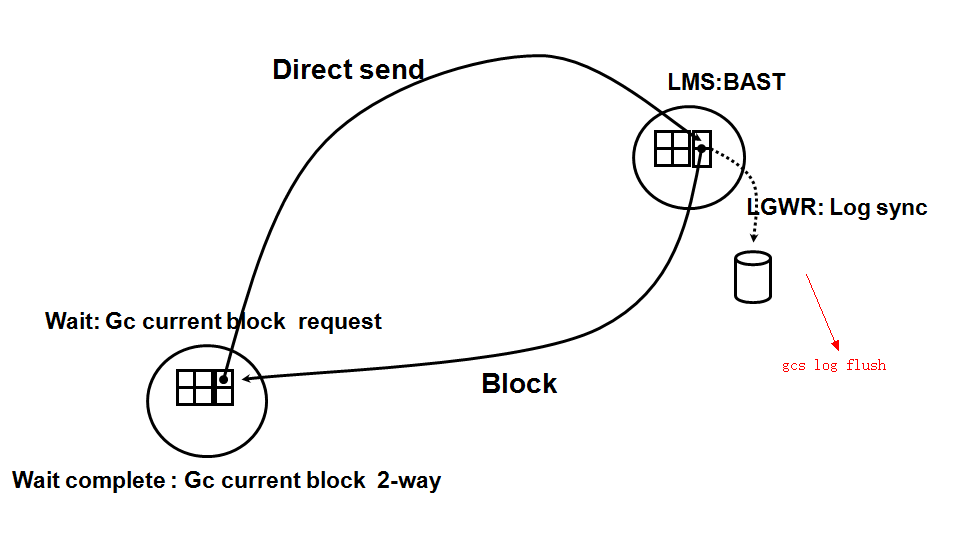
而gc buffer busy acquire/release 往往是 gc current block busy的衍生产品, 当同一实例内的多个进程并发地访问同一个数据块时 ,首先发起的进程
将进入 gc current block busy的等待 ,而在 buffer waiter list 上的后续进程 会陷入gc buffer busy acquire/release 等待(A user on the same
instance has started a remote operation on thesame resource and the request has not completed yet or the block was requestedby another node and the block has not been released by the local instance whenthe new local access was made), 这里存在一个排队效应, 即 gc current block
busy是缓慢的,那么在 排队的gc buffer busy acquire/release就会更慢:
Pin time = (timeto read the block into cache) + (time to modify/process the buffer)
Busy time =(average pin time) * (number of interested users waiting ahead of me)
不局限于current block (reference AWR Avg global cache current block flush time(ms)), cr block(Avg global cache cr block flush time (ms))
也存在flush time。
可以通过设置_cr_server_log_flush to false(LMSare/is waiting for LGWR to flush the pending redo during CR fabrication.Without going too much in to details, you can turn off the behaviourby setting _cr_server_log_flush to false.) 来禁止crserver flush redo log,但是该参数对于
current block的flush time无效, 也强烈不推荐使用。
三.gc cr multi blockrequest等待事件
gc cr multiblock request实际就是globalcache cr multi block request,10G以后global cache被简称为gc,在RAC应用系统里面,这是一个常见等待事件。
multi block一般情况下都是全表扫描或全索引扫描导致, gc cr multiblock request 会造成CPU 对内存的调度和管理,会消耗CPU 时间。
gc cr multiblock request 问题应在rac 层面上进行应用分离,即不同节点处理不同应用,节点之间通过配置,做为彼此的备用节点,在节点宕机时可以结果
相关应用,提供高可用性。
--转自

 发起投票
发起投票

 技术讨论
技术讨论






 加好友
加好友 发消息
发消息 2015-11-10 14:47:16 |
2015-11-10 14:47:16 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}