当使用 Hadoop 技术架构集群,集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值时,都会造成集群内数据分布不均匀、数据丢失风险增加等问题出现。
并行计算模型和框架
目前开源社区有许多并行计算模型和框架可供选择,按照实现方式、运行机制、依附的产品生态圈等可以被划分为几个类型,每个类型各有优缺点,如果能够对各类型的并行计算框架都进行深入研究及适当的缺点修复,就可以为不同硬件环境下的海量数据分析需求提供不同的软件层面的解决方案。
并行计算框架
并行计算或称平行计算是相对于串行计算来说的。它是一种一次可执行多个指令的算法,目的是提高计算速度,以及通过扩大问题求解规模,解决大型而复杂的计算问题。所谓并行计算可分为时间上的并行和空间上的并行。时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
国内外研究
欧美发达国家对于并行计算技术的研究要远远早于我国,从最初的并行计算逐渐过渡到网格计算,随着 Internet 网络资源的迅速膨胀,因特网容纳了海量的各种类型的数据和信息。海量数据的处理对服务器 CPU、IO 的吞吐都是严峻的考验,不论是处理速度、存储空间、容错性,还是在访问速度等方面,传统的技术架构和仅靠单台计算机基于串行的方式越来越不适应当前海量数据处理的要求。国内外学者提出很多海量数据处理方法,以改善海量数据处理存在的诸多问题。
目前已有的海量数据处理方法在概念上较容易理解,然而由于数据量巨大,要在可接受的时间内完成相应的处理,只有将这些计算进行并行化处理,通过提取出处理过程中存在的可并行工作的分量,用分布式模型来实现这些并行分量的并行执行过程。随着技术的发展,单机的性能有了突飞猛进的发展变化,尤其是内存和处理器等硬件技术,但是硬件技术的发展在理论上总是有限度的,如果说硬件的发展在纵向上提高了系统的性能,那么并行技术的发展就是从横向上拓展了处理的方式。
2003 年美国 Google 公司对外发布了 MapReduce、GFS、BigData 三篇论文,至此正式将并行计算框架落地为 MapReduce 框架。
我国的并行和分布式计算技术研究起源于 60 年代末,按照国防科技大学周兴铭院士提出的观点,到目前为止已经三个阶段了。第一阶段,自 60 年代末至 70 年代末,主要从事大型机内的并行处理技术研究;第二阶段,自 70 年代末至 90 年代初,主要从事向量机和并行多处理器系统研究;第三阶段,自 80 年代末至今,主要从事 MPP(Massively Parallel Processor) 系统研究。
尽管我国在并行计算方面开展的研究和应用较早,目前也拥有很多的并行计算资源,但研究和应用的成效相对美国还存在较大的差距,有待进一步的提高和发展。
MapReduce
MapReduce 是由谷歌推出的一个编程模型,是一个能处理和生成超大数据集的算法模型,该架构能够在大量普通配置的计算机上实现并行化处理。MapReduce 编程模型结合用户实现的 Map 和 Reduce 函数。用户自定义的 Map 函数处理一个输入的基于 key/value pair 的集合,输出中间基于 key/value pair 的集合,MapReduce 库把中间所有具有相同 key 值的 value 值集合在一起后传递给 Reduce 函数,用户自定义的 Reduce 函数合并所有具有相同 key 值的 value 值,形成一个较小 value 值的集合。一般地,一个典型的 MapReduce 程序的执行流程如图 1 所示。
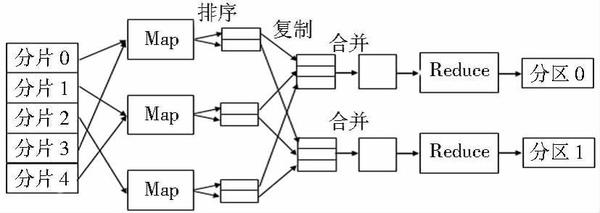
图 1 .MapReduce 程序执行流程图
MapReduce 执行过程主要包括:
将输入的海量数据切片分给不同的机器处理;
执行 Map 任务的 Worker 将输入数据解析成 key/value pair,用户定义的 Map 函数把输入的 key/value pair 转成中间形式的 key/value pair;
按照 key 值对中间形式的 key/value 进行排序、聚合;
把不同的 key 值和相应的 value 集分配给不同的机器,完成 Reduce 运算;
输出 Reduce 结果。
任务成功完成后,MapReduce 的输出存放在 R 个输出文件中,一般情况下,这 R 个输出文件不需要合并成一个文件,而是作为另外一个 MapReduce 的输入,或者在另一个可处理多个分割文件的分布式应用中使用。
Hadoop MapReduce
Hadoop 的设计思路来源于 Google 的 GFS 和 MapReduce。它是一个开源软件框架,通过在集群计算机中使用简单的编程模型,可编写和运行分布式应用程序处理大规模数据。Hadoop 包含三个子项目:Hadoop Common、Hadoop Distributed File System(HDFS) 和 Hadoop MapReduce。
第一代 Hadoop MapReduce 是一个在计算机集群上分布式处理海量数据集的软件框架,包括一个 JobTracker 和一定数量的 TaskTracker。运行流程图如图 2 所示。
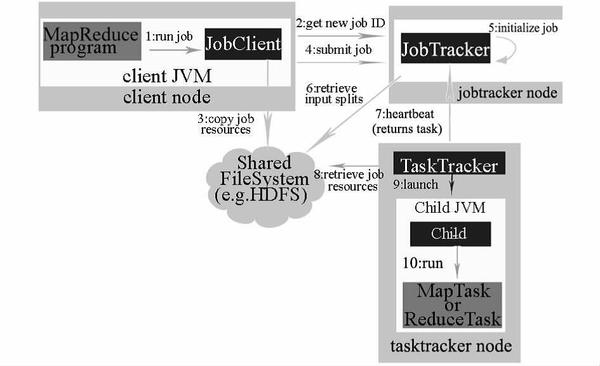
图 2 .Hadoop MapReduce 系统架构图
在最上层有 4 个独立的实体,即客户端、JobTracker、TaskTracker 和分布式文件系统。客户端提交 MapReduce 作业;JobTracker 协调作业的运行;JobTracker 是一个 Java 应用程序,它的主类是 JobTracker;TaskTracker 运行作业划分后的任务,TaskTracker 也是一个 Java 应用程序,它的主类是 TaskTracker。Hadoop 运行 MapReduce 作业的步骤主要包括提交作业、初始化作业、分配任务、执行任务、更新进度和状态、完成作业等 6 个步骤。
Spark MapReduce
Spark 是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速。Spark 非常小巧玲珑,由加州伯克利大学 AMP 实验室的 Matei 为主的小团队所开发。使用的语言是 Scala,项目的核心部分的代码只有 63 个 Scala 文件,非常短小精悍。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 提供了基于内存的计算集群,在分析数据时将数据导入内存以实现快速查询,“速度比”基于磁盘的系统,如比 Hadoop 快很多。Spark 最初是为了处理迭代算法,如机器学习、图挖掘算法等,以及交互式数据挖掘算法而开发的。在这两种场景下,Spark 的运行速度可以达到 Hadoop 的几百倍。
Disco
Disco 是由 Nokia 研究中心开发的,基于 MapReduce 的分布式数据处理框架,核心部分由 Erlang 语言开发,外部编程接口为 Python 语言。Disco 是一个开放源代码的大规模数据分析平台,支持大数据集的并行计算,能运行在不可靠的集群计算机上。Disco 可部署在集群和多核计算机上,还可部署在 Amazon EC2 上。Disco 基于主/从架构 (Master/Slave),图 3 总体设计架构图展示了通过一台主节点 (Master) 服务器控制多台从节点 (Slave) 服务器的总体设计架构。
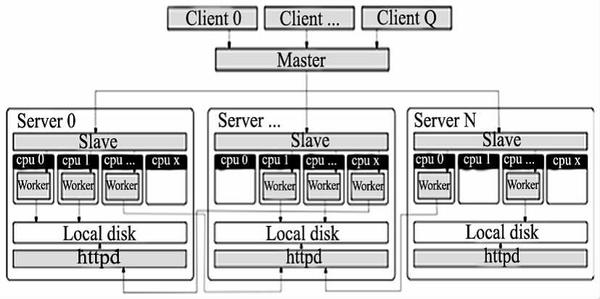
图 3 .Disco 总体架构图
Disco 运行 MapReduce 步骤如下:
Disco 用户使用 Python 脚本开始 Disco 作业;
作业请求通过 HTTP 发送到主机;
主机是一个 Erlang 进程,通过 HTTP 接收作业请求;
主机通过 SSH 启动每个节点处的从机;
从机在 Worker 进程中运行 Disco 任务。
Phoenix
Phoenix 作为斯坦福大学 EE382a 课程的一类项目,由斯坦福大学计算机系统实验室开发。Phoenix 对 MapReduce 的实现原则和最初由 Google 实现的 MapReduce 基本相同。不同的是,它在集群中以实现共享内存系统为目的,共享内存能最小化由任务派生和数据间的通信所造成的间接成本。Phoenix 可编程多核芯片或共享内存多核处理器 (SMPs 和 ccNUMAs),用于数据密集型任务处理。
Mars
Mars 是香港科技大学与微软、新浪合作开发的基于 GPU 的 MapReduce 框架。目前已经包含字符串匹配、矩阵乘法、倒排索引、字词统计、网页访问排名、网页访问计数、相似性评估和 K 均值等 8 项应用,能够在 32 位与 64 位的 Linux 平台上运行。Mars 框架实现方式和基于 CPU 的 MapReduce 框架非常类似,也由 Map 和 Reduce 两个阶段组成,它的基本工作流程图如图 4 所示。
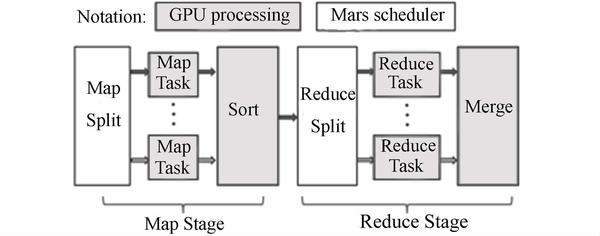
图 4 .Mars 基本工作流程图
在开始每个阶段之前,Mars 初始化线程配置,包括 GPU 上线程组的数量和每个线程组中线程的数量。Mars 在 GPU 内使用大量的线程,在运行时阶段会均匀分配任务给线程,每个线程负责一个 Map 或 Reduce 任务,以小数量的 key/value 对作为输入,并通过一种无锁的方案来管理 MapReduce 框架中的并发写入。
Mars 的工作流程主要有 7 个操作步骤:
在主存储器中输入 key/value 对,并将它们存储到数组;
初始化运行时的配置参数;
复制主存储器中的输入数组到 GPU 设备内存;
启动 GPU 上的 Map 阶段,并将中间的 key/value 对存储到数组;
如果 mSort 选择 F,即需要排序阶段,则对中间结果进行排序;
如果 noReduce 是 F,即需要 Reduce 阶段,则启动 GPU 上的 Reduce 阶段,并输出最终结果,否则中间结果就是最终结果;
复制 GPU 设备存储器中的结果到主存储器。
上述步骤的 1,2,3,7 这四个步骤的操作由调度器来完成,调度器负责准备数据输入,在 GPU 上调用 Map 和 Reduce 阶段,并将结果返回给用户。
五种框架的优缺点比较
表 1. 五种框架优缺点比较

如果用户只需要处理海量的文本文件,不需要考虑存储、二次数据挖掘等,采用 Phoenix 或者 Mars 是最大性价比的选择,但是由于 Mars 必须在 GPU 上运行,本身 GPU 由于价格因素,导致不太可能在实际应用场景里推广,所以综合来看 Phoenix 是性价比最高的框架。如果应用程序需要处理的数据量非常大,并且客户希望计算出的数据可以被存储和二次计算或数据挖掘,那 Hadoop MapReduce 较好,因为整个 Hadoop 生态圈庞大,支持性很好。Apache Spark 由于架构层面设计不同,所以对于 CPU、内存的使用率一直保持较低状态,它未来可以用于海量数据分析用途。
--转自

 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2015-7-22 9:46:49 |
2015-7-22 9:46:49 |
 赞(
赞( 操作
操作


 不明觉厉
不明觉厉{kind=link}
{kind=link}