曾经有段时间,大概两年前,SQL-on-Hadoop就要打开Hadoop的数据访问。这是基于以下两个原因:SQL自有的那些特征,消除Hadoop/MapReduce专家对数据访问的排他性。是的,一些架构细节也是重要的,比如SQL引擎是否直接触及Hadoop集群的数据节点。但是,大多数情况下,解决方案被巧妙地概括为:SQL,on Hadoop。
今天,SQL-on-Hadoop解决方案被认为是最好的,不是因为他们SQL引擎自身,而是他们能够使得Hadoop和传统数据仓库协作。Hadoop可以视为篡位者,数据仓库的同等或者外围部分;SQL-on-hadoop引擎,用来决定Hadoop这三个角色哪一个(或者更多)能被实现完成。
Gigaom研究刚刚发布行业路线:Hadoop/数据仓库互操作性。分析师George Gilbert调查了SQL-on-Hadoop市场,评估了六个解决方案。这六个“中断向量”的每一个或者主要趋势将影响市场和明年的玩家:模式灵活性、数据引擎互操作性、定价模式、企业可管理性、负载优化作用和查询引擎的成熟度。
场景
作为根据这些向量评价各种SQL-on-Hadoop产品的背景,Gilbert确定三个关键分析使用场景。第一个是核心数据仓库,许多学院派专家熟悉的概念:一个相当昂贵的基于硬件数据库平台提供高度组织化的数据,它的数据结构被优化为商业认为需要运行的查询类型。
第二个是所谓的“数据湖”(被一些厂商称为“企业数据中心”)。这里,Hadoop充当各种不同数据来源的收集点,包括无结构化,半结构化和结构化数据。Hadoop 2.0的YARN资源管理器促进使用各种分析引擎以特别的方式去探索“湖”的数据,由此数据仓库能够解脱出来,自由为设计和调整的查询服务。
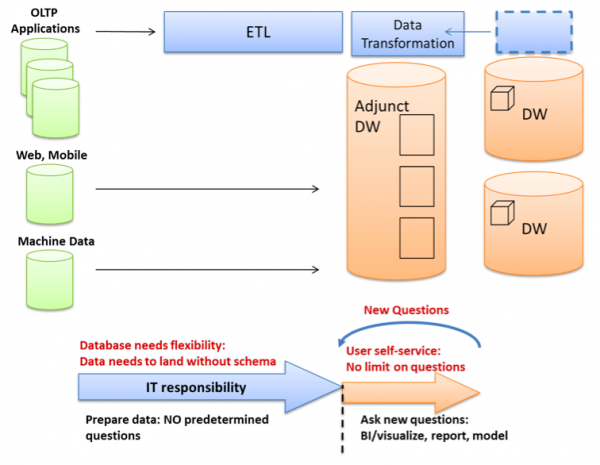
实际上,核心数据仓库,辅助数据仓库和数据湖构成数据处理层次,并具有相应层次的成本。平台的分层选择能够使得较低产值的任务(不过,可以说,更高的商业价值)在较便宜的平台上处理——为企业组织产生更高的效率。
企业投资回报率
便宜了多少呢?Gilbert说,Hadoop成本每TB数据与基于硬件的数据仓库相比,至少少一个数量级。因为Hadoop能够启用数据湖和辅助数据库场景,他们的实现能够使Hadoop给企业用户明显的投资回报率。
一个悬而未决的问题是,是否并且何时Hadoop能够同样地在核心数据仓库中提供服务。如果能这样做,这将有助于数据仓库供应商,Hadoop分销商或者两者兼而有之?确实,这种动态性可能是预测未来分销商兼并由传统玩家主导——或者可能甚至是相反的。
--转自

 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2015-5-18 10:00:35 |
2015-5-18 10:00:35 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}