多模算法简介
多模式匹配在这里指的是在一个字符串中寻找多个模式字符字串的问题。一般来说,给出一个长字符串和很多短模式字符串,如何最快最省的求出哪些模式字符串出现在长字符串中是我们所要思考的。该算法广泛应用于关键字过滤、入侵检测、病毒检测、分词等等问题中。多模问题一般有Trie树,AC算法,WM算法等等。我们将首先介绍这些常见算法。
1.hash
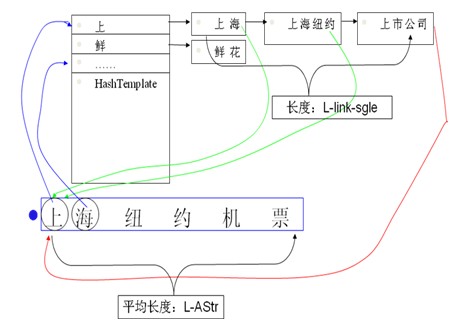
可以单字、双字、全字、首尾字hash。
优点:简单、通常有效
缺点:受最坏情况制约,空间消耗大,需要回朔。
2.Trie树
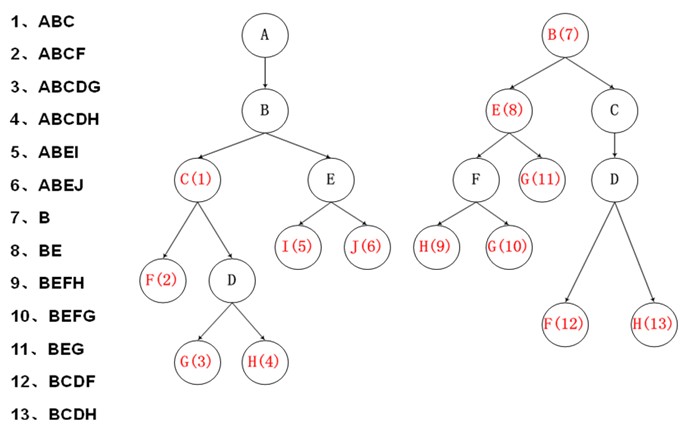
改进:进行穿线,参考KMP的算法,进行相同前缀匹配,建立跳转路径,避免回朔。
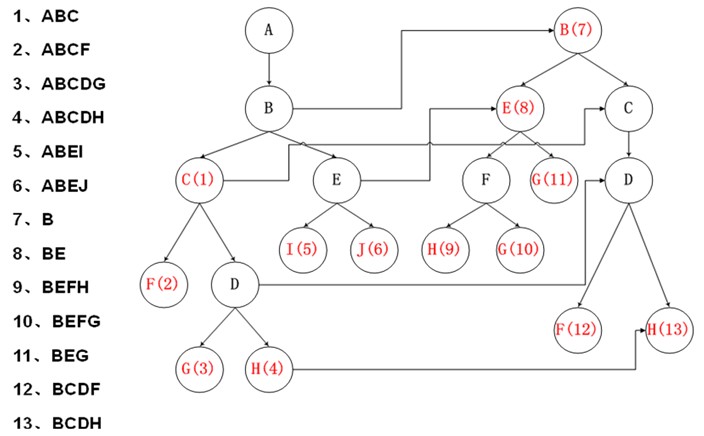
跳转路径建立的算法思想:
如果要建立节点 A -> A’ 的 跳转路径需要满足:
1)A = A’ 节点有相同的value值,代表同一个字
2)A的深度>A’的深度
3)对于A节点的父节点F,和A’节点的父节点(如果有父节点的话),有F->F’
优点:无回朔,查询效率一般较高
缺点:数据结构复杂难以维护,浪费空间多,建树时间长。
3.AC算法
本质上来说和Trie树一样。
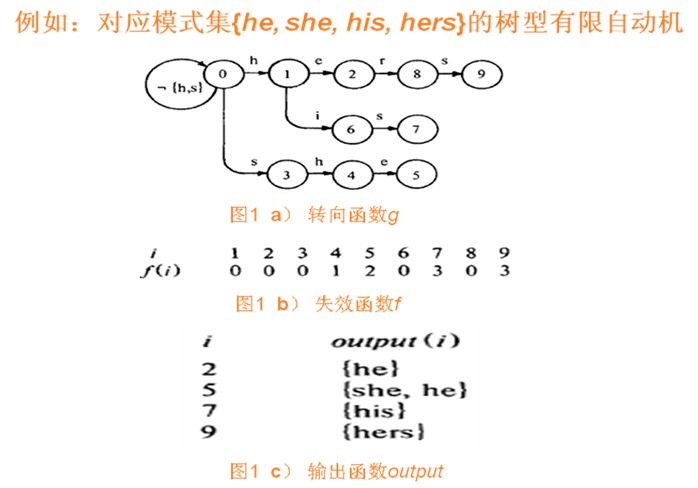
转向函数:建立一个根据输入字符转变状态的有限自动机
失效函数:当出现状态无法根据输入字符继续走时,需要根据失效函数转化当前状态。失效函数的建立需要满足:节点r深度之前都已建立失效函数f。则若有g(r, a) = s,回朔r’=f( r )直至找到g(r’, a) 存在,则将f(s)=g(r’, a)。和Trie树是一致的。实际上,如果某状态节点r对输入字符a无路径,则可以将该节点的失效函数f( r )指向的状态节点r’的g(r’, a)作为g(r, a)。这样在搜索中就不需要专门考虑失效节点的问题了,只需要沿着转向函数一直走。
输出函数:某状态代表着匹配某模式的结束,因此输出函数的值就是匹配成功模式的集合。因为模式之间可能会有互包含,因此可能有多个成功匹配的模式。
AC算法比Trie树数据结构简单,因此运用广泛。用于snort等代码中。
4.WM算法
先讲BM算法。BM算法是KMP之外的另一个单模式字符串匹配算法,其思想也很简单:
假设模式串是P 主串是T, m=strlen(P),n=strlen(T)
从左向右移动模式串
对于模式串的匹配, 从右向左检查, 也就是P[m-1],p[m-2]...
当发现不匹配时, 使用好后缀和/或坏字符来决定模式串移动的距离 通常同时使用两个来加快查找速度
当发现一个不匹配时 如下:
Consider a mismatch at P[n - 5]:
T: mahtava talomaisema omalomailuun
P: maisemaomaloma
上面 m != t ,
这时 T 中的 t字符叫做坏字符,P 中的字符 "aloma" 叫做好后缀
坏字符算法:
当出现一个坏字符时, BM算法向右移动模式串, 让模式中最靠右的对应字符与坏字符相对。然后继续匹配。移动距离可预先计算为delta1(x) = m - max{k|P[k] = x, 1 <= k <= m}; (x出现在P中)。
好后缀算法:
如果程序匹配了一个好后缀, 并且在模式中还有另外一个相同的后缀, 那把下一个后缀移动到当前后缀位置(类似KMP 只是KMP是从左向右移动)。移动距离delta2可预先计算为delta2(j)= {s|P[j+1..m]=P[j-s+1..m-s]) && (P[j]≠P[j-s])(j>s)}。
BM算法在查找开始时 先根据模式串中所有字符建立一个坏字符表,然后创建一张好后缀表。在匹配过程中,取max{delta1, delta2}作为实际移动的离尾部的距离,即尽量移动距离最大。
BM算法的最坏时间复杂度为O(m*n),但实际比较次数只有文本串长度的20%~30%。可以看作是亚线性的时间复杂度算法。
WM算法的思想从BM算法思想演变而来,但是用于多模匹配中。WM算法也是从右到左进行匹配。WM算法有一个重要假设,假设所有的模式的字符串长度是一样的,为m。若不一样,则按最短的那个模式长度在做匹配时截断其他的模式。
WM算法将建立三张表:SHIFT[], HASH[], PREFIX[]。其中,SHIFT表用于决定匹配时出现失配的情况时的移动距离,类似于BM算法中的坏字符策略。HASH和PREFIX表则用于当SHIFT表匹配成功不需要移动后,决定是否具体匹配到某个模式的问题。
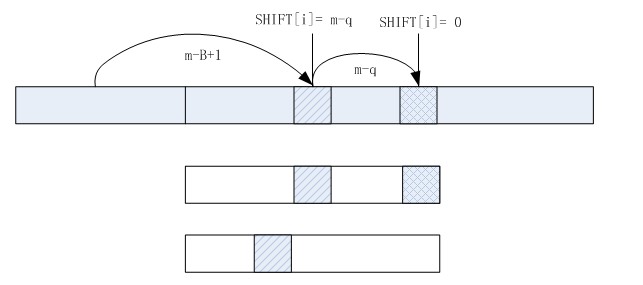
SHIFT表:考虑一块大小为B的字符块,而不是单纯的一个字符。一般取B=2或3。SHIFT为长度为B的一切可能的字符排列都建立一个索引,因此其下标的大小就是所有可能的长度为B的排列数。(实际上,可以通过压缩的策略将一些排列串弄到相同的空间)。SHIFT 中每一项的值决定在文本中出现某B 个字符组成的字符串时pattern 的移动距离,也就是在所有的pattern中出现的最右的B离pattern尾部的距离。假设X为当前计算的B长字符块,且被hash为i,考虑两种情况:
第一:X 不在任何一个pattern 中出现,我们可以将当前text考察的位置向后移动m-B+1 个字符的距离,于是我们在SHIFT[i]中存放m-B+1。
第二:X 在某些pattern 中出现,这种情况下,我们考察那些pattern 中X 出现的最右位置。假设,X 在P[j]中的q 位置出现,且在其他的出现X 的pattern 中X 的位置都不大于q。那么我们应该在SHIFT[i]中存放m-q。
最后我们将得到SHIFT 表,表中存放的值是我们text 中出现某一长为B 的字符串时能够移动的最大的安全距离。当检查pos位置,得到其B块的hash值为i,当SHIFT[i]<> 0 时,pos=pos + SHIFT,跳动。
HASH表:当SHIFT[i]=0时使用。SHIFT[i]=0时,代表匹配串当前位置的X可能匹配上了某个(某些)模式的尾部。因此HASH[i]指向了尾部B长的字符块散列值为i的模式链表的头p。我们可以将所有的模式以尾部B长的字符块的散列值进行排序存放在某个模式表数组中,则只需要依次递增p就可以找到所有尾部散列值为i的模式,直到p = hash[i+1],代表了该链表的尾部。
PREFIX表:当SHIFT[i]=0时,且通过HASH表列出了所有可能的模式时使用。通过对每个模式头部B’个字符进行hash,将其散列值放在PREFIX表中。HASH[i]中的指针同时也是指向PREFIX表的,通过比较PREFIX[p]和匹配串的头B’个字符的hash值,能够进一步确定是哪个模式匹配上了。最终,对该模式和匹配串的每一个字符进行一一匹配确定是否匹配。
如果SHIFT[i]=0,且检查匹配完成,则pos = pos + 1,继续检查pos位置的SHIFT。
实践证明,大部分时间SHIFT都不为0,(在一个典型的例子中,对于100个模式5%的时间移动值为0,1000个模式27%的时间移动值为0,5000个模式53%的时间。),也就代表匹配串是跳跃着前进的,因此可以达到亚线性的时间复杂度。经过计算,复杂度为O(mp)+ O(BN/m),设N是文本的大小,P是模式的数量,m是每个模式的长度。
优点:快速,数据结构简单,实现容易。
缺点:需要所有模式长度基本相同(不能有太短的模式),不支持变长的编码,例如GB18030。
 发起投票
发起投票

 技术讨论
技术讨论







 加好友
加好友 发消息
发消息 2012-11-15 10:19:34 |
2012-11-15 10:19:34 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}