转自公众号 人工智能头条
什么是胶囊网络?
胶囊网络是Geoffrey Hinton 提出的一种新型神经网络结构,为了解决卷积神经网络(ConvNets)的一些缺点,提出了胶囊网络。
话不多说,来看看这个听起来就像「一颗一颗药摆在你面前」的网络是怎么样的。
卷积网络有平移不变性
平移不变性是什么呢?假设我们有一个可以分类猫的模型,你给这个模型看一张猫的图片,它会预测出这是一只猫。然后你把猫向左移一下,再展示给这个模型看,它依然会认为这是一只猫,而不会预测出其他的信息。

这样看来好像不错,意味着无论这只猫放在图片的哪个位置,我们的模型都能识别出这是一只猫,好像它表现得还不错。但是有的时候我们需要的是平移同变性。也就是当我们给这个模型展示一张移动到右边的猫的图片时,模型预测的是一只移动到右边的猫;展示一张移动到左边的猫的图片时,模型预测的是一只移动到左边的猫。

为什么要平移同变性呢?一般我们给一个模型输入一张人脸的图片的时候,五官都是在正常的位置的,眼睛在眼睛的位置上,鼻子在鼻子的位置上。但是我们如果把眼睛放在额头上,耳朵放在下巴那,一般的卷积神经网络还是会认为这是一张脸,因为它有平移不变性,也就是它只认为一张有鼻子有眼睛有嘴巴等特征的脸,就是人脸。让我们来看一下这样一张奇怪的人脸是怎样的。
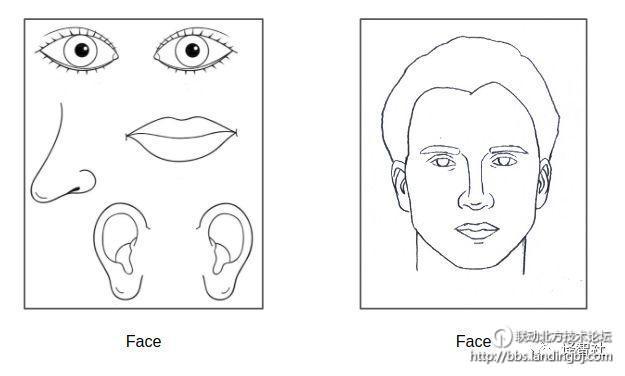
如果胶囊网络像我们所说的那样有平移同变性,那么它就能够识别到人脸的某一部分与另一部分的相对位置不正确,并且把这一部分正确的标注出来:
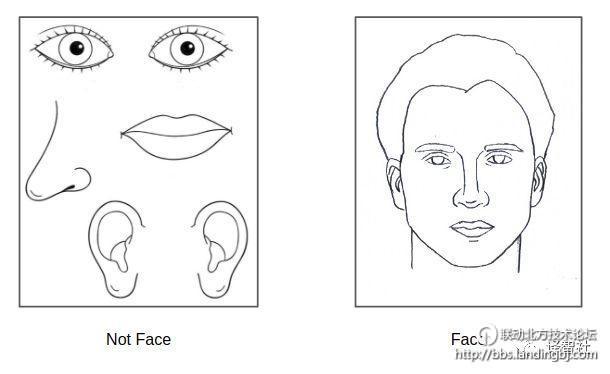
卷积网络需要大量的数据来泛化
为了使卷积神经网络具有平移不变量,模型必须为每个不同的观测角度学习不同的滤波器,而这样就需要大量的数据来进行。
卷积网络在人类视觉系统上的表现很差
根据Hinton 所说的,当视觉刺激被触发的时候,大脑里面有一种内在的机制,将低层次的视觉数据「导航」到它认为可以最好地处理这些数据的部分。而卷及网络使用多层滤波器来从底层可视数据中提取高级信息,所以这种导航机制就不存在了。
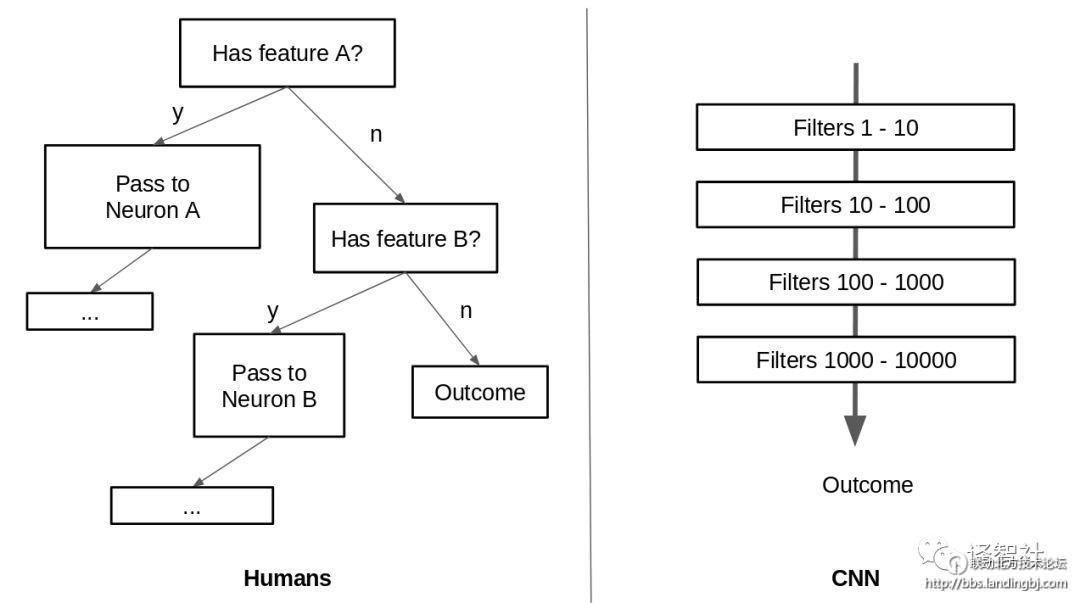
而且,当人类在看一个物体的时候,视觉系统会在坐标系上表示这个物体。就好比我们可以知道一个图形是不是给翻转了。
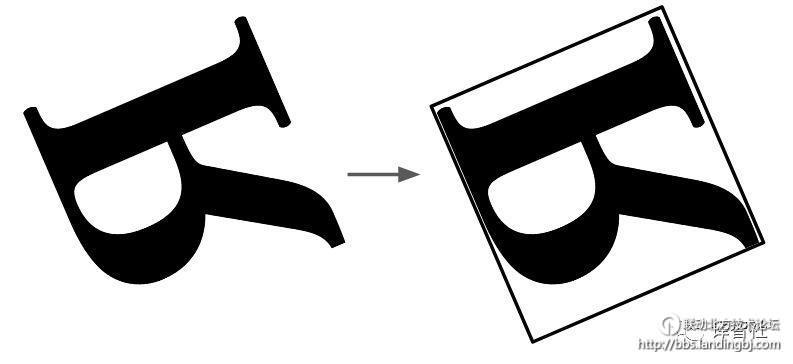
当我们看到上面的这个字母时,我们是会在脑里边默默地把他旋转到一个它们一般所放置的参考点,类似于:
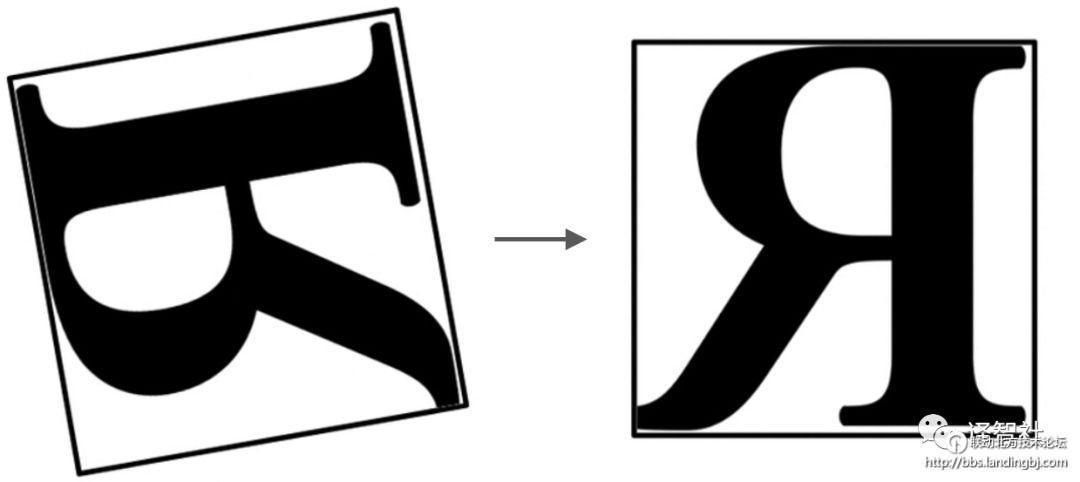
而由于卷积网络其设计的特性,它就不会有这样的操作。那么稍后,我们将探讨如何设置一个边框,并对对象进行相对于其坐标的旋转。
胶囊网络是怎么解决这些问题的?
你可以把(电脑)视觉想象成「逆图像 」—— Geoffrey Hinton
什么是逆图像呢?简单地说,它就是电脑在屏幕上渲染的物体的一个相反映射。(这听起来好像有点难理解,但是当你看完下面的文字和图片,应该会有较大帮助)
为了把一个网格物体变成像素在屏幕上显示出来,电脑会取这整个物体的姿态,然后与一个变换矩阵相乘。这样就会在一个较低的维度(2D)输出物体部分的姿态,这就是我们在屏幕上所看到的画面了。
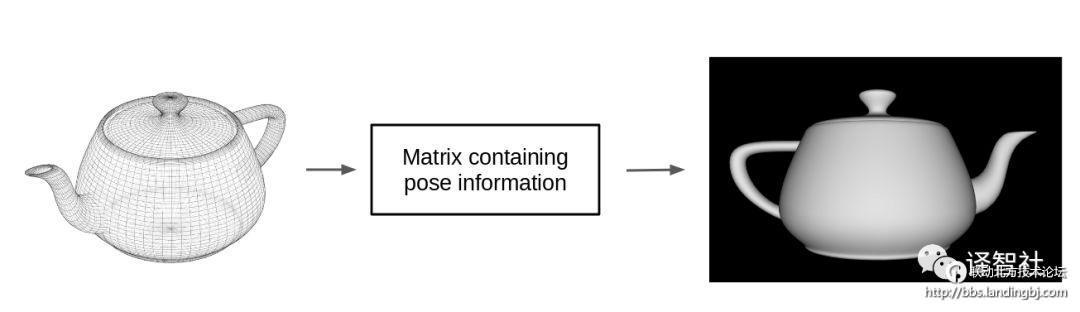
那么为什么我们不能反过来做呢?让低维空间的像素图片去乘以变换矩阵的逆,来得到整个物体的姿态。
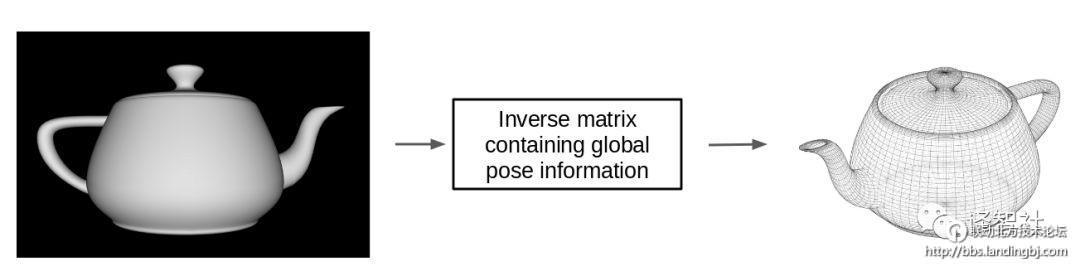
这样做可不可以的呢?答案是:可以的(不过只是在近似的水平上)!这样做的话,我们就可以把一个物体作为整体表示,而把部分的姿态作为权重矩阵来表示,并且表现出两者的关系。而这些权重矩阵是视角不变的,也就是说,不管部分的姿态怎么变化,我们都使用同样的权重矩阵可以得到整体的姿态。
这让我们在权重矩阵中完全独立于物体的观测角度。平移不变性现在只在权重矩阵中表现出来了,而不是在(网络)神经活动中表现。
得到权重矩阵
来看看在胶囊网络的论文中是怎么讲的。
注:图片内容由英语原文翻译。
在Hinton 的论文中,他说胶囊网络使用了一个重构的损失函数来作为正则化方法,类似于自编码器的操作。这样为什么会有效呢?
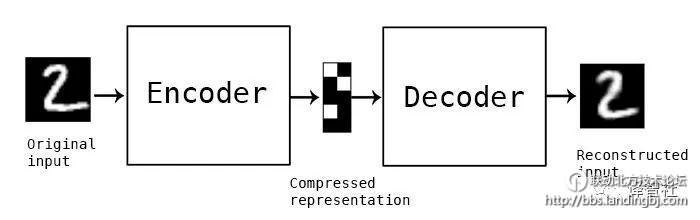
为了从较低维度空间中重构输入,编码器和译码器需要学习一个好的矩阵表示,来联系潜在空间和输入的关系,听起来是不是很熟悉?
总之,利用重构的损失函数作为正则方法,胶囊网络能够通过无监督学习,在在整个物体和物体的姿态之间学习一个全局线性复本来作为权重矩阵。因此,平移不变性就封装在这个权重矩阵中而不是在神经活动中,这样就使得神经网络有平移同变性。因此,在某种意义上,当图片和全局线性复本相乘时,就是在做一个「旋转和平移」的操作。
动态路径规划
路径规划是把信息传播给另一个能够更加高效处理信息的操作者的行为。路径规划在卷积网络中就是通过池化层来进行的,而且基本上都是使用的极大值池化。
极大值池化是做路径规划的一个很原始的方式,它只让在池化中最活跃的神经元起作用。而胶囊网络就不同了,它会把信息传给上层中最擅长处理的胶囊。
结论
胶囊网络使用一个模仿人类视觉系统的的新架构,来获得平移同变性,代替原来的平移不变性,使得它在不同的视角下可以使用更少的数据得到更广的泛化。
该贴被liuliying930406编辑于2018-11-23 17:41:11
 发起投票
发起投票

 技术讨论
技术讨论








 加好友
加好友 发消息
发消息 2018-11-21 12:51:42 |
2018-11-21 12:51:42 |
 赞(
赞( 操作
操作
{kind=link}
{kind=link}